《Java》备忘录
本文用于记录 Java 相关知识,以备查阅。
01 面向对象
面向对象的三大特征:
- 封装:通过访问修饰符实现,优点是减少耦合,提高软件的可重用性
- 继承:通过 extends 实现,表示 is-a 的关系
- 多态:编译时多态指的是方法的重载,运行时多态指的是对象引用所指向的具体类型在运行期间才确定,运行时多态通过继承,重写,向上转型实现
02 基础知识
数据类型:8 种基本类型,对应 8 种包装类型,通过 xxxValue 和 valueOf 自动拆箱和装箱
缓存池:
- 基本类型:除了 long,float 和 double,其它类型都有一字节的缓存池
- String:字面量创建会先从常量池获取,没有的话再创建,new 创建不会加入常量池
String:被声明为 final,内部存储的 value 数组也被声明为 final,同时内部没有改变 value 指向的方法,因此保证了 String 类不可变,不可变的好处:
- 可以缓存 hash 值
- String Pool 的需要,如果可变将没有意义
- 安全性和线程安全
String,StringBuilder,StringBuffer:
- String 不可变,StringBuilder 和 StringBuffer 可变
- String 和 StringBuffer 是线程安全的,StringBuilder 不是线程安全的
String.intern:可以保证相同内容的字符串变量引用同一的内存对象,其首先将字符串对象放到字符串常量池中,然后返回这个对象引用
参数传递:Java 中的参数是以值传递的形式传入方法中的,而不是引用传递
float 和 double:浮点数字面量默认是 double 类型,需要加后缀 f 将其表示为 float 类型
隐式类型转换:整型数字面量是 int 类型,使用复合运算符如 += ,会自动类型转换
switch:从 Java 7 开始,支持 String 对象(对应的 hashcode ),但是其仍旧不支持 long
访问权限:
- 类可见:其它类可以用这个类创建实例对象
- 成员可见:其它类可以用这个类的实例对象访问到该成员
| 访问权限 | 本类 | 本包的类 | 子类 | 非子类的外包类 |
|---|---|---|---|---|
| public | 是 | 是 | 是 | 是 |
| protected | 是 | 是 | 是 | 否 |
| default | 是 | 是 | 否 | 否 |
| private | 是 | 否 | 否 | 否 |
抽象类和接口:
- 抽象类:一般会包含抽象方法,抽象方法一定位于抽象类中,不能被实例化
- 接口:是抽象类的延伸,在 Java 8 开始,引入了默认方法
- 比较:
- 抽象类提供了 is-a 的关系,而接口提供了 like-a 关系
- 一个类只能继承一个抽象类,但是可以实现多个接口
- 接口的字段只能是 static 和 final ,成员(字段和方法)只能是 public
super:
- 访问父类的构造函数,需要放到子类构造函数第一行
- 访问父类的成员
重写和重载:
- 重写:存在于继承体系中,为了满足里式替换原则,需要满足
- 参数列表和父类相同
- 子类方法的访问权限必须大于等于父类方法
- 子类方法的返回类型必须是父类方法返回类型或为其子类型
- 重载:存在于同一个类中,指方法名相同,但是参数类型,个数,顺序至少有一个不同,应该注意的是,返回值不同,其它都相同不算是重载
Object 通用方法:getClass,hashCode,equals,clone,toString,notify,notifyAll,wait,finalize
equals 方法实现:
- 检查是否为同一个对象的引用,如果是直接返回 true
- 检查是否是同一个类型,如果不是,直接返回 false
- 将 Object 对象进行转型
- 判断每个关键域是否相等
hashCode:用于返回对象的哈希值,通常将每个字段看作是 R 进制中的某一位,R 一般取 31
clone:是 Object 类的 protected 方法,并不是 public,如果想要重写该方法,还需要实现 Cloneable 空接口。分为浅拷贝和深拷贝两种方式,可以使用更加安全的拷贝构造函数来拷贝一个对象
final:
- 修饰数据时,表示数据是常量,对于引用类型,只是使其引用不变
- 修饰方法时,表示方法不能被重写,private 方法隐式地指定为 final
- 修饰类时,表示类不可被继承
static:
- 静态变量:类变量,所有实例共享静态变量
- 静态方法:在类加载的时候就存在了,不能是抽象方法,不能包含 this 和 super
- 静态语句块:类初始化时运行一次
- 静态内部类:非静态内部类依赖于外部类的实例,而静态内部类不需要
- 静态导包:不用指定类名就可以使用方法,但是可读性降低
- 初始化顺序:静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。在存在继承的情况下:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
Java 7 版本新特性:
- Strings in Switch Statement
- Type Inference for Generic Instance Creation
- Multiple Exception Handling
- Support for Dynamic Languages
- Try with Resources
- Java nio Package
- Binary Literals, Underscore in literals
- Diamond Syntax
Java 8 版本新特性:
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed:限制了加载类的空间大小,改为元空间,不受限大小
Java 和 C++ 区别:
- Java 是纯粹的面向对象语言,C++ 既支持面向对象也支持面向过程
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针
- Java 支持自动垃圾回收,而 C++ 需要手动回收
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承
- Java 不支持操作符重载,而 C++ 可以
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto
- Java 不支持条件编译,C++ 通过 #ifdef #ifndef 等预处理命令从而实现条件编译
03 泛型机制
引入泛型的意义:
- 适用于多种数据类型执行相同的代码
- 使用泛型可以提供编译前的检查,不需要强制类型转换,更加安全
泛型的使用:
- 泛型类
- 泛型接口
- 泛型方法:相比泛型类,其更加灵活,在使用不同的参数的时候,不需要再次实例化一个对象
泛型的上下限:为类型参数增加限制
- 上限:
<T extends Number>,注意,extends 后面可以是接口,表示实现了接口的类型 - 下限:
<T super String>,表示 T 是 String 或者 String 的父类(Object) - 无限制通配符:
<T>或者<?> - 多个限制:
<T extends A & B >或者<T extends A , B >,通常一个类和多个接口
类型擦除:Java 中实现泛型的方式是在编译阶段进行类型擦除,即
- 将所有泛型表示都替换为具体的类型
- 为了保证类型安全,必要时插入强制类型转换
- 自动产生桥接方法保证擦除后的代码具有泛型的多态性
证明类型擦除:
原始类型相同:如
ArrayList<String>和ArrayList<Integer>的 getClass 返回值相同通过反射可以添加其他类型的元素:
strList.getClass().getMethod("add", Object.class).invoke(list, "asd")
原始类型:指擦除了泛型信息,最后在字节码中的类型变量的真正类型
泛型的编译期检查:Java 编译期会先检查代码中泛型的类型,然后再进行类型擦除,之后进行编译
类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象
参数化类型不考虑继承关系,下面的引用传递不被允许:
1
2
3
4// 编译错误,ClassCastException
ArrayList<String> list1 = new ArrayList<Object>();
// 编译错误,违背使用泛型的初衷
ArrayList<Object> list2 = new ArrayList<String>();
泛型的多态实现:类型擦除会造成多态的冲突,JVM 采用桥接方法解决该问题
1 | class DateInter extends Pair<Date> { |
另外,子类中桥接方法 Object getValue() 和 Date getValue() 是同时存在的,虚拟机可以通过返回值和参数类型来区别,但是在编写程序的时候,Java 编译期不允许我们这样做。
基本类型不能作为泛型类型:无限制泛型擦除后将变为 Obejct,而 Obejct 不能存储 int 等基本类型
泛型类型不能实例化:本质上由于类型擦除造成的,如果确实需要实例化泛型,可以使用反射
泛型数组:采用通配符的方式初始化泛型数组(存在警告),因为对于通配符的方式最后取出数据是要做显式类型转换的,符合预期逻辑。更加优雅的方式是使用反射:Array.newInstance
泛型类中的静态方法和静态变量:不可以使用泛型类所声明的泛型类型参数,因为静态变量和静态方法不需要使用对象来调用,从而类型参数不确定,但是可以使用泛型静态方法
获取泛型的参数类型:通过反射 java.lang.reflect.Type 获取
04 注解机制
注解分类:
- Java 自带的标准注解:
@Override,@Deprecated,@SupressWarning - 元注解:用于定义注解的注解
- 自定义注解:根据自己需求定义注解
自带的标准注解:
@Override:表示当前的方法定义将覆盖父类中的方法@Deprecated:表示代码被弃用,如果使用了被 @Deprecated 注解的代码则编译器将发出警告@SuppressWarnings:表示关闭编译器警告信息
元注解:描述注解的注解
@Target:描述注解的使用范围,取值范围在 ElementType 枚举类中@Retention:描述注解保留的时间范围,取值范围在 RetentionPolicy 中,共三种@Documented:描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息@Inherited:被它修饰的注解将具有继承性,被该注解修饰的父类,其子类自动具有该注解@Repeatable:允许在同一申明类型(类,属性,或方法)的多次使用同一个注解@Native:修饰成员变量,则表示这个变量可以被本地代码引用,常常被代码生成工具使用
注解和反射:通过反射下的 AnnotatedElement 接口可以获取注解,要求该注解范围是 RUNTIME 的
注解不支持继承:尽管在内部实现中,注解被翻译成 interface,但是并不能使用 extends 来继承某个 @interface,另外,在注解编译后,编译器会自动将其继承到 Annotation 接口
注解使用场景:
- 配置化到注解化:框架的演进
- 继承实现到注解实现:junit3 到 Junit4
- 自定义注解和 AOP:通过切面实现解耦
05 异常机制
异常结构层次:
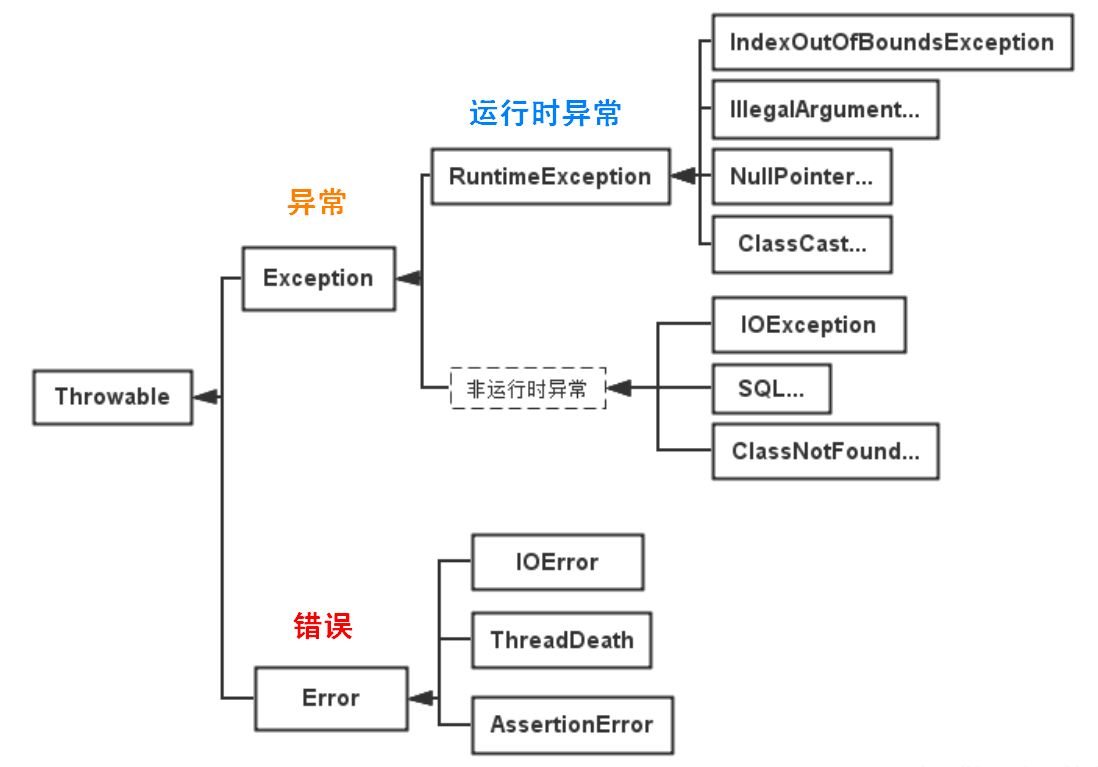
- 可查异常:编译器要求必须处理的异常,包括非运行时异常
- 不可查异常:编译器不强制要求处理的异常,包括运行时异常和错误
异常关键字:try,catch,fainally,throw,throws
异常的声明(throws):在方法末尾添加该语句即可,添加异常的规则
- 如果是不可查异常,那么可以不使用 throws 来声明,因为在运行时会被系统抛出
- 必须声明任何方法可抛出的的可查异常
- 重写方法声明的异常必须是被重写方法声明的异常或者其子类
异常的抛出(throw):有时在 catch 中抛出一个异常,目的是为了改变异常的类型
异常自定义:通过继承异常类实现,可以实现带有详细描述信息的构造函数用于调试
异常的捕获:
- try-catch:同一个 catch 可以捕获多种不同的异常,使用
|分割 - try-catch-finally:不管有没有出现异常,finally 中的语句块始终会被执行,通常 finnaly 里面不要包含 return 语句
- try-finally:保证资源使用后被关闭
- try-with-resource:自动释放资源,需要资源实现了 AutoCloseable 接口的类
异常实践:
- 只针对不正常的情况才使用异常,如可以通过判断规避掉 NullPointorException
- 使用 finally 或者 try-with-resources 关闭资源
- 尽量使用标准的异常,基于语义的基础
- 对异常进行文档说明
- 优先捕获最具体的异常
- 不要捕获 Throwable 类,因为其会捕获 Error(如 OOM)
- 不要忽略异常,至少记录异常的信息
- 不要记录并抛出异常,可能导致多个地方输出同一个异常信息
- 包装异常时不要抛弃原始的异常,否则失去了原始的堆栈信息
- 不要使用异常控制程序的流程
- 不要在 finally 块中使用 return,会覆盖 try 块中的返回点
JVM 处理异常的机制:编译器通过编译后,会生成对应的异常表,异常表每项表示为(from,to,target,type),表示在 [from, to] 代码段中可能发生异常,如果发生 type 类异常,就跳转到 target 对应的代码段。在发生异常的时候,JVM 查找异常表,跳转到对应的 target 地方
异常耗时:建立一个异常对象,大概是一个普通 Object 对象的 20 倍,而抛出,接收一个异常,所花费时间大约是建立异常对象的 4 倍
06 反射机制
反射机制:在运行时,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性。
Class 类:Class 类也是一个类,其实例用于表示运行时的类(class & enum)或接口(interface & annotation),数组和基本类型同样也被映射为 Class 对象的一个类
- 手动编写的类编译后会产生 Class 对象,其被保存在同名 .class 文件中
- 每个类在内存中只有一个对应的 Class 对象来描述其信息,采用单例模式
- Class 类只存在私有构造函数,因此对应的 Class 对象只能通过 JVM 加载和创建
Class 类对象的获取:
- 根据类名:类名.class
- 根据对象:对象.getClass()
- 根据全限定类名:Class.forName(全限定类名)
Constructor 类:表示 Class 对象所表示类的构造方法,相关方法如下:
- getConstructor(Class<?>… parameterTypes):返回具有 public 访问权限的构造函数对象
- getDeclaredConstructor(Class<?>… parameterTypes):返回所有(包括 private)构造函数对象
- newInstance():调用无参构造器创建新的实例
- newInstance(Object… initargs)
Field 类:提供有关类或接口单个字段的信息,以及对它的动态访问权限
- getField:获取指定的名称,且具有 public 修饰的字段,包括继承字段
- getDeclaredField:获取指定的字段(包括 private),不包括继承的字段
- set(Object obj, Object value) & get(Object obj):不可设置 final 字段
- setAccessible(boolean flag):设置其可访问性,用于访问 private 属性
Method 类:提供关于类或接口上单独某个方法的信息
- getMethod(String name, Class<?>… parameterTypes)
- getDeclaredMethod(String name, Class<?>… parameterTypes)
- invoke(Object obj, Object… args)
反射调用流程:
- 反射类和反射方法的获取,都是通过从列表中顺序搜寻查找匹配的方法
- 当找到需要的方法时,都会 copy 一份出来,保证数据隔离
- 每个类都可以获取 method 反射方法,并作用到其他实例身上
- 反射也是线程安全的
- 反射使用 reflectionData 缓存 Class 信息,避免开销
07 SPI 机制
SPI 机制:JDK 内置的服务提供发现机制,可以用来启用框架扩展和替换组件。服务提供者定义接口后,需要在 classpath 下的 META-INF/services/ 目录下创建一个服务接口命名的文件,这个文件里的内容就是这个接口具体的实现类。
SPI 机制:JDBC DriverManager,在以前开发时,需要先 Class.forName 加载数据库相关的驱动,而在 JDBC4.0 之后直接获取连接就可以了
- JDBC 接口定义:java 中定义了接口
java.sql.Driver,但是没有具体实现 - 实现:
- mysql:在 mysql 的 jar 包中,可以找到
META-INF/services目录,该目录下面有一个java.sql.Driver的文件,文件内容是com.mysql.cj.jdbc.Driver - postgresql:在对应的目录下面,也可以找到对应的配置文件
- mysql:在 mysql 的 jar 包中,可以找到
- 使用方法:直接通过
DriverManager.getConnection来获取连接,实际执行代码的步骤- 从系统变量中获取有关驱动的定义
- 使用 SPI 来获取驱动的实现:
ServiceLoader.load - 遍历使用 SPI 获取到的具体实现,实例化各个实现类
SPI 的缺点:
- 不能按需加载,需要遍历所有的实现并实例化(懒加载),然后在循环中才能找到我们需要的实现
- 获取某个实现类的方式不灵活,只能通过 Iterator 形式获取
- 不是并发安全的
08 Collection 类
集合类:集合类用于容纳其他的 Java 对象,其只能存放对象,基本类型通常需要装包和解包
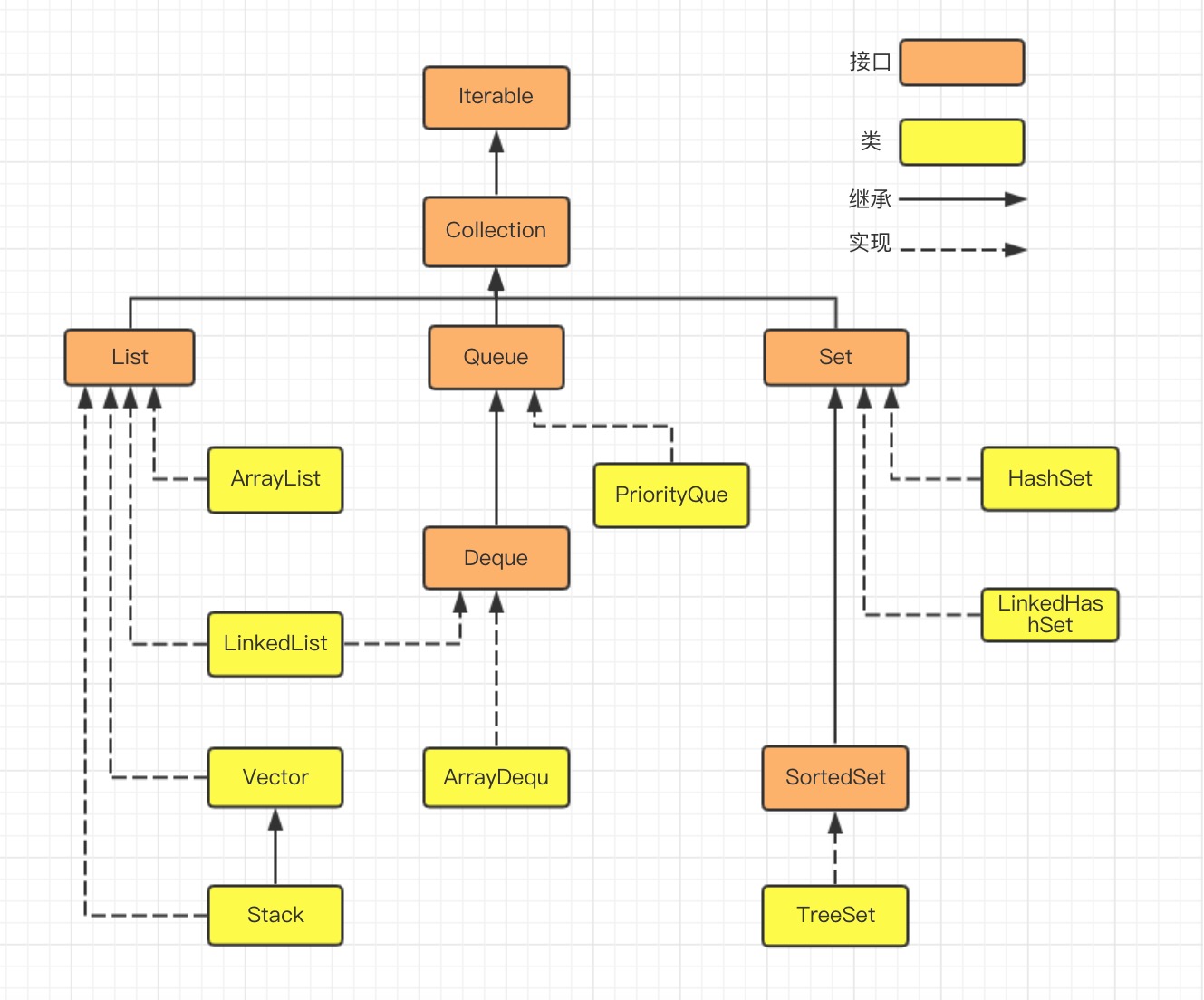
Collection:存储对象的集合
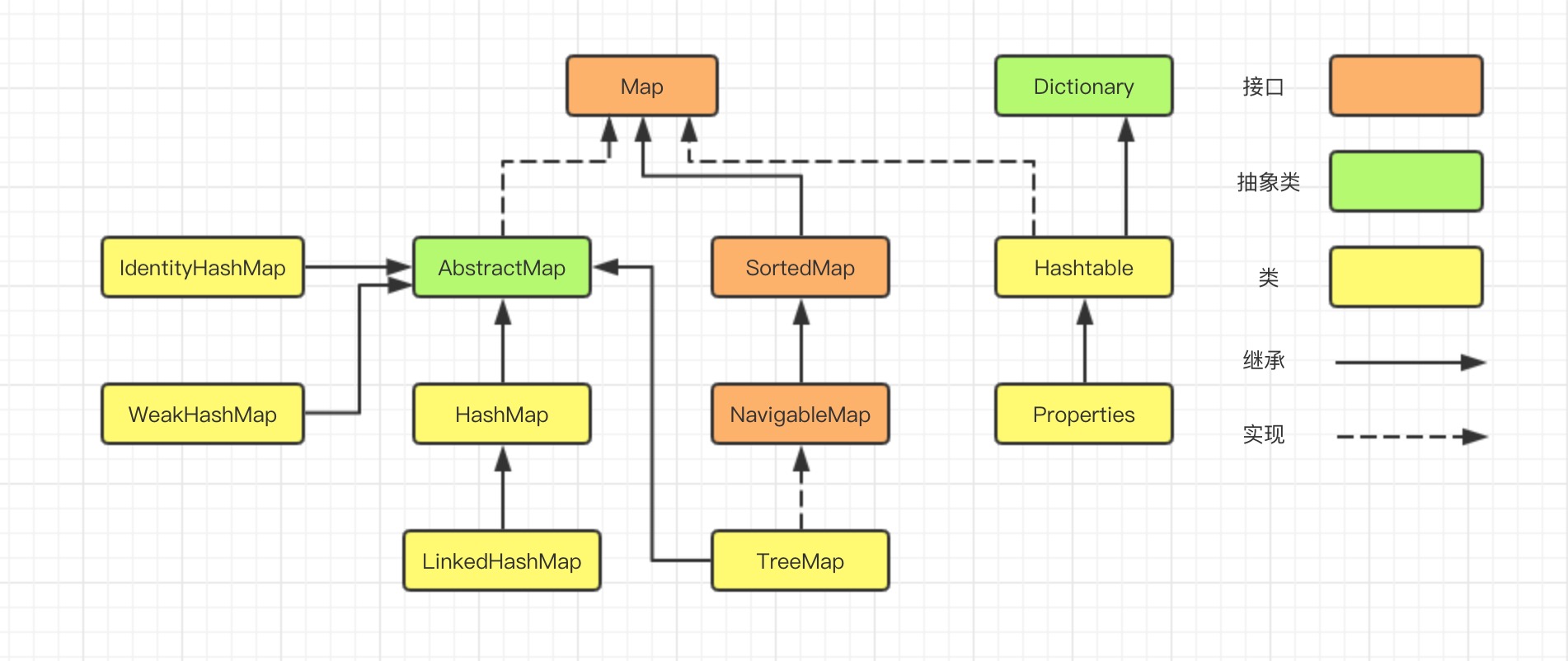
Map:存储键值对的映射表
ArrayList:实现了 List 接口,允许存放 null 元素,底层通过 Object 数组实现,以便容纳任何类型的对象,为了追求效率,并没有实现线程同步
- add,addAll,get,set,remove,indexOf,lastIndexOf
- 自动扩容:如果添加数据时,超过 capacity 值,就会自动扩容,每次扩容变为之前容量的 1.5 倍,在实际添加大量元素前,可以通过 ensureCapacity 来提前分配
- Fail-Fast:采用了快速失败机制,记录 modCount 参数来实现,在并发修改时,迭代器很快就会失败
LinkedList:底层是带有头尾节点的双向链表,同时实现了 List 接口和 Deque 接口,即可以看作是顺序容器,又可以看作是一个队列,同时可看作一个栈。不过关于栈或者队列,现在首选的是 ArrayDeque,其有着更好的性能。如果需要多个线程并发访问,可以采用 Collections.synchronizedList() 进行包装
- getFirst,getLast,removeFirst,removeLast,remove,add,addAll,clear,set,get
- Queue 方法:offer,poll,peek,remove,element
- Deque 方法:offerFirst,offerLast,peekFirst,peekLast,pollFirst,pollLast,removeFirstOccurrence,removeLastOccurrence
Stack:当需要使用栈时,推荐使用更高效的 ArrayDeque
Queue:支持两组格式的 api
- 抛出异常:add,remove,element
- 返回值(null)实现:offer,poll,peek
Deque:同样支持两组格式的 api,无非是如 offerFirst/offerLast 格式,ArrayDeque 实现了 Deque 接口,其底层采用循环数组实现
PriorityQueue:优先队列保证每次取出的元素都是队列中权值最小的(默认),元素大小即可以通过元素本身自然顺序,也可以通过构造时传入的比较器,不允许放入 null 元素,通过完全二叉树实现的小顶堆,意味着可以通过数组作为底层数据结构
- 抛出异常:add,element,remove
- 返回值:offer,peek,poll
HashMap:实现了 Map 接口,既允许 key 为 null,也允许 value 为 null,该类未实现线程同步
插入:为了解决冲突,采用冲突链表方式,采用头插法进行插入
hashcode 决定了对象会被放到哪个 bucket 中,当多个对象的哈希值冲突时,equals 方法决定了这些对象是否是同一个对象
数组扩容:有两个参数会影响 HashMap 的性能,初始容量和负载系数,负载系数用来指定自动扩容的临界值,当 entry 的数量超过
capacity * load_factor时,容器将自动扩容并且重新哈希,每次扩容后容量为原来的 2 倍Java 7 采用链表和数组实现 HashMap:

Java 8 采用链表,数组和红黑树实现,主要不同在于当链表中的元素超过 8 个时,会将链表转换为红黑树,使得在进行查找的时候降低时间复杂度
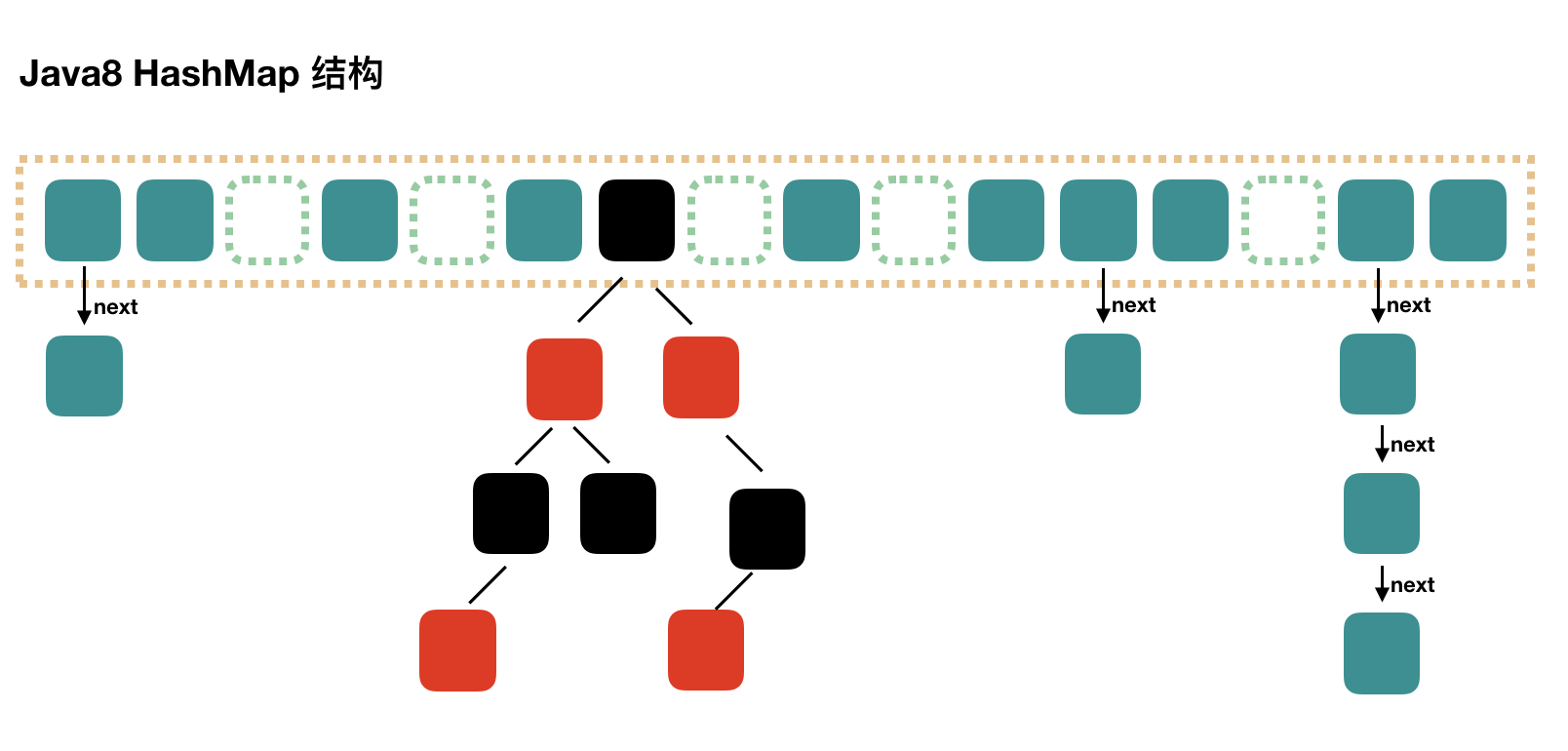
HashSet:对 HashMap 的一个简单封装,对 HashSet 的函数调用都会转换成合适的 HashMap 方法
LinkedHashMap:实现了 Map 接口,可以看作是 linkedlist 增强的 hashmap,其采用双向链表的形式将所有的 entry 连接起来,这样是为了保证元素的迭代顺序和插入顺序相同,另外,遍历的时候只需要从 header 开始遍历即可,遍历的时间复杂度和元素个数相同

TreeMap:实现了 SortedMap 接口,会按照 key 的大小顺序对 Map 中的元素排序,其底层采用红黑树
- ceilingKey,floorKey,higherKey,lowerKey
- headMap,tailMap
- descendingKeySet,pollFirstEntry,pollLastEntry,subMap
WeakHashMap:里面的 entry 可能会被 GC 自动删除,即使程序员没有调用 remove 或者 clear 方法
- 用于需要缓存的场景,这是在于缓存 miss 并不会造成错误
- 弱引用:虽然弱引用可以用来访问对象,但是在进行垃圾回收时并不会被考虑在内,仅有弱引用指向的对象依旧会被 GC 回收
- 并没有 WeakHashSet:可以通过
Collections.newSetFromMap
09 IO 知识体系
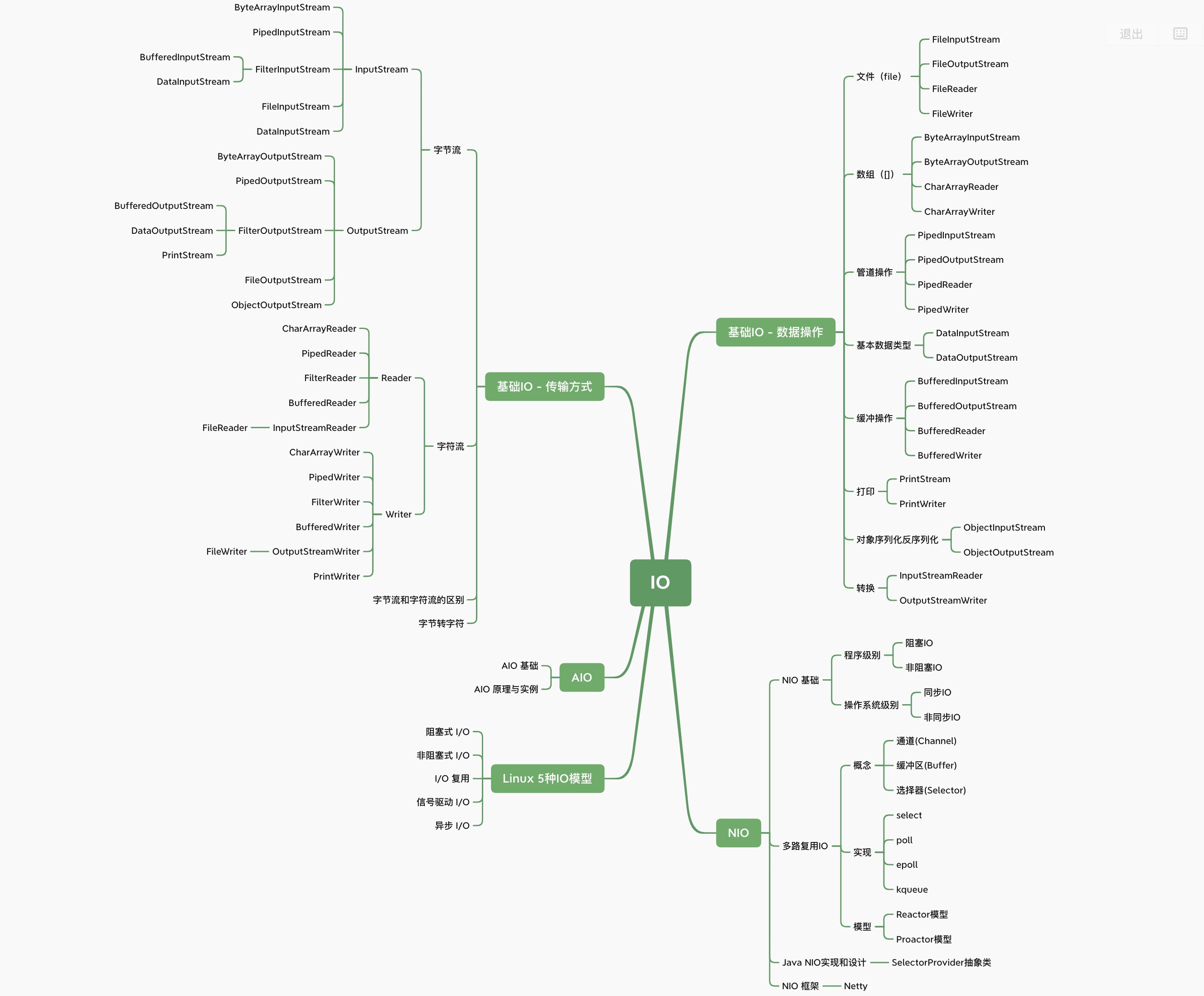
IO 分类:
- 传输方式:
- 字节流:读取单个字节,用来处理二进制文件
- 字符流:读取单个字符,用来处理文本文件
- 操作对象:文件,数组,管道,基本数据类型,打印,对象,缓冲,转换
字节转字符:通过 {Input,Output}Stream{Reader,Writer} 实现,char 类型使用 UTF-16be 编码
IO 设计模式:装饰者模式,FilterInputStream 属于抽象装饰者,为组件提供额外功能,如缓冲
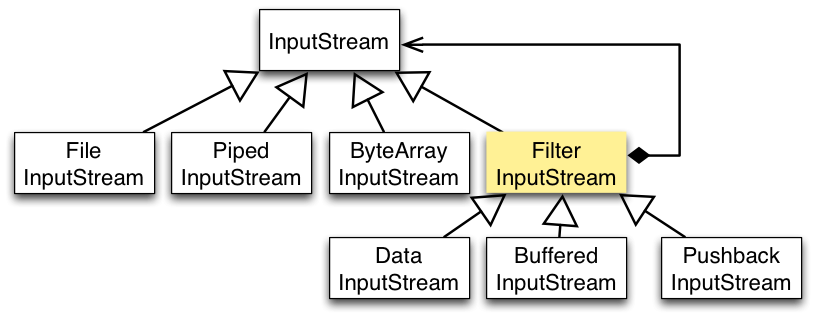
IO 常见类的使用:
- 磁盘操作:File,表示文件和目录的信息
- 字节操作:InputStream 和 OutputStream
- 字符擦做:Reader 和 Writer
- 对象操作:Serializable,只是一个标准接口,transient 关键字可以让某些属性不被序列化
- 网络操作:Socket
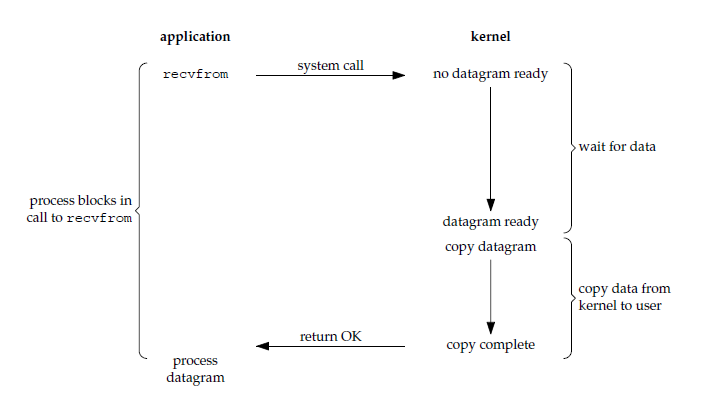
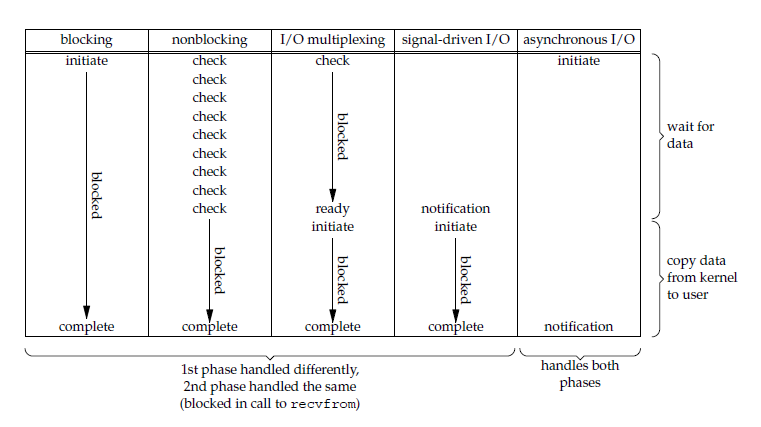
Unix 下的五种 IO 模型:
阻塞式 IO:
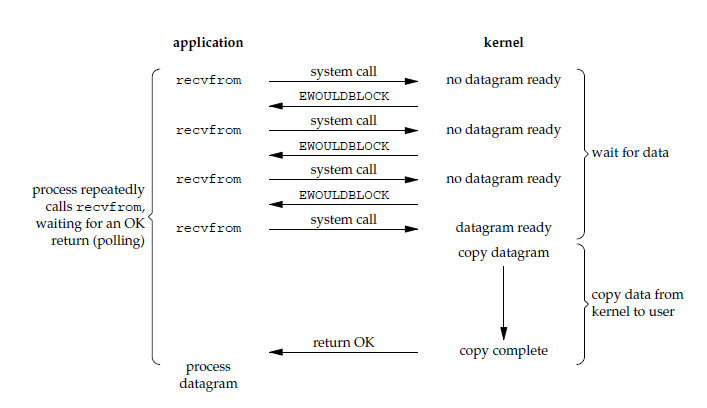
非阻塞式 IO:
多路复用 IO:
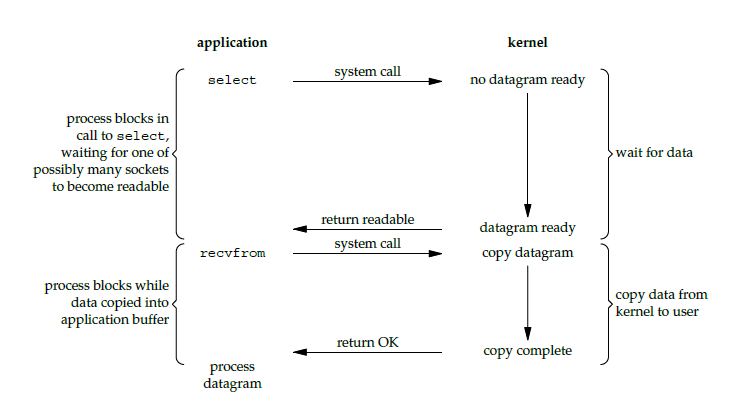
信号驱动 IO:
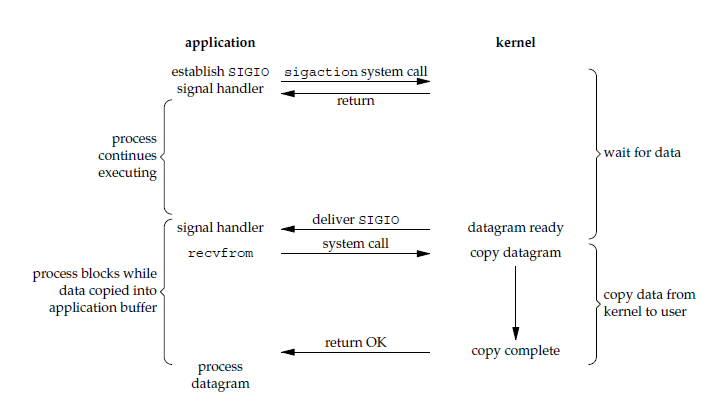
异步 IO:应用进程在调用 recvfrom 操作时不会阻塞
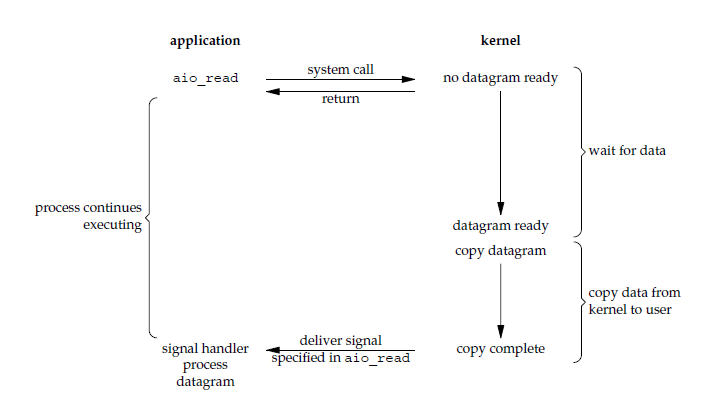
五种 IO 模型的对比:
IO 多路复用:
- 工作模式:
- LT 模式:当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程,默认模式,同时支持 Blocking 和 No-Blocking
- ET 模式:通知之后进程必须立即处理事件,下次不会对该事件通知,减少了 epoll 事件被重复触发的次数,效率高些,只支持 No-Blocking,防止出现饿死情况
- 应用场景:
- select:timeout 参数精度 1ns,而 poll 和 epoll 为 1ms,更加适用于实时性要求高的场景,同时兼容性也好一些
- poll:没有最大描述符数量的限制,如果需要监控的描述符状态变化多,而且都是非常短暂的,没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率
- epoll:只需要运行在 linux 上,并且有非常大量的描述符需要同时轮询
IO 概念区分:
- 阻塞 IO 和 非阻塞 IO:程序级别,当程序请求 OS IO 操作后,如果 IO 资源没有准备好,应该如何处理
- 同步 IO 和 异步 IO:操作系统级别,当程序请求 OS IO 操作后,如果 IO 资源没有准备好,该如何响应
BS 架构发展:
- 单线程:服务器同时只能处理单个请求,会造成多个客户端等待问题
- 多线程:accept 使用单线程方式,处理请求时使用多线程或者线程池,但是 accept 和 read 还是阻塞
Java IO 和 NIO 区别:
- 是否阻塞:IO 是阻塞的,NIO 则是非阻塞的
- 操作粒度:
- IO 中对流进行操作,读写操作按照字节为单位,简单,但是效率低
- NIO 中对通道进行操作,读写操作按照块为单位,高效,但是缺少简单性
NIO 相关概念:
- 通道:是对流的模拟,通过通道可以读取并写入数据,即双向的
- 缓冲区:发送和接受通道中的数据都需要首先放到缓冲区中,包括 capacity,position 和 limit 成员,通过 flip 可以切换缓冲区的读写状态
- 选择器:通过轮询的方式去监听多个通道上的事件,让一个线程可以处理多个事件
- 创建选择器:Selector.open
- 将通道注册到选择器上:ssChannel.register,注册事件可以是 accept,也可以是 read & write
- 监听事件:selector.select,会阻塞直到至少一个事件到达
- 获取到达的事件:selector.selectedKeys
- 事件循环
内存映射文件:是一种读写文件数据的方法,比常规的基于流和基于通道的 IO 快得多,通过 fc.map 创建该映射缓冲 MappedByteBuffer,就可以像使用 ByteBuffer 一样使用它
典型的多路复用 IO 实现:
| IO模型 | 性能 | 关键思路 | 操作系统 | JAVA 支持情况 |
|---|---|---|---|---|
| select | 较高 | Reactor | windows/Linux | Reactor 模式 |
| poll | 较高 | Reactor | Linux | Linux 下的 JAVA NIO 框架 |
| epoll | 高 | Reactor/Proactor | Linux | 使用 epoll 进行支持 |
| kqueue | 高 | Proactor | Linux | 不支持 |
Reactor 模型:基于事件驱动,主要包括三个组件:
- Reactor:等待客户端的连接,并将其派发给 Acceptor
- Acceptor:进行客户端连接的获取,之后交给线程池进行网络读写
- Handler:用于处理连接的网络读写操作,并进行事务处理(可以交给线程池)
Java AIO 模型:由于此时采用的是订阅-通知方式,不需要 slector 了,改为 channel 直接到操作系统注册监听,windows 底层通过 IOCP 支持,linux 底层通过 epoll 模拟实现
Java NIO 框架:
- 原生 Java NIO 框架:基于 IO 多路复用
- Mina:在 Java NIO 基础上提供了抽象的事件驱动程序 API
- Netty:提供异步的、事件驱动的网络应用程序框架和工具,综合性能最优
- Grizzly:使用JAVA NIO作为基础,并隐藏其编程的复杂性
Java NIO 零拷贝基础:
- 通道:相当于操作系统的内核空间的缓冲区,全双工的
- 缓冲区:相当于操作系统的用户空间的缓冲区,分为堆内存和堆外内存
- 堆内存:在 GC 的时候可能会被自动回收,在 NIO 读写数据时,会将其临时拷贝到堆外内存
- 堆外内存(DirectBuffer):在使用后需要手动回收,通过 malloc 实现
MappedByteBuffer:基于内存映射实现,继承自 ByteBuffer,如 FileChannel 中的 map 方法
- 写文件数据:put & fore
- 读文件数据:get
- 实现原理:void *mmap64(void *addr, size_t len, int prot, int flags, int fd, off64_t offset)
DirectByteBuffer:通过 DirectByteBuffer 静态方法 allocateDirect 分配内存,是 MappedByteBuffer 的具体实现类,因此,其本身也具有文件内存映射的功能
FileChannel:用于文件读写,映射和操作的通道,并且是线程安全的
- transferTo:把文件里面的源数据写入一个 WritableByteChannel 的目的通道
- transferFrom:把一个源通道 ReadableByteChannel 中的数据读取到当前 FileChannel 的文件里面
- transferTo 底层实现和 sendfile64 相关
RocketMQ 和 Kafka 对比:

10 Java 虚拟机
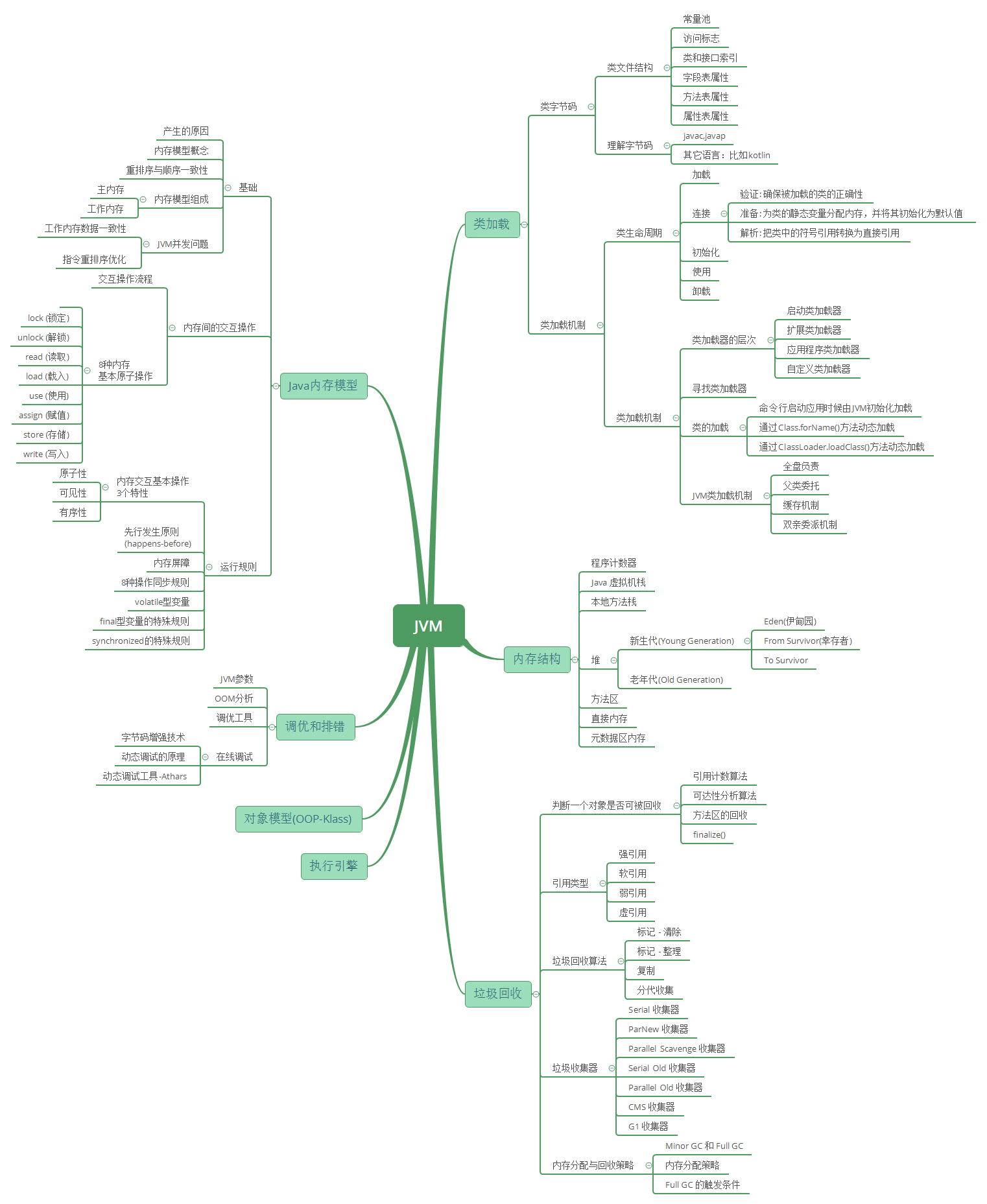
字节码文件:java 文件首先被编译为字节码文件,然后 JVM 在不同操作系统运行字节码文件,优点:
- 一次编写,处处执行
- 由于 JVM 直接运行字节码文件,可支持其他语言,如 Kotlin,scala,groovy 语言
字节码文件结构:
- 魔数和文件版本:开头四个字节为魔数,预期值是 0xCAFEBABE
- 常量池:字节码文件的资源仓库,主要存放字面量和符号引用等
- 访问标志:表示字节码文件的类型(类/接口),访问类型,是否标记为 final
- 类索引,父类索引,接口索引
- 字段表属性:描述接口或类中声明的变量,如作用域,是否 static,final,数据类型
- 方法表属性:和字段表类似
反编译字节码文件:javac -g <javafile> && javap -v -p <classfile>,相关信息解释
- 访问标志:如
- ACC_SUPER:是否允许使用 invokespecial 字节码指令的新语义
- ACC_SYNTHETIC:标志这个类并非由用户代码产生
- ACC_ANNOTATION:标志这是一个注解
- 类型信息:基本类型通常首字母表示,但是存在特例:
- long 类型:J
- boolean 类型:Z
- 对象类型:L,如 Ljava/lang/Object;
- 数组:[,如定义一个
String[][]类型的数组,记录为[[Ljava/lang/String;
- 方法表:Code 段里面的属性:
- stack:最大操作数栈,JVM 根据这个分配栈帧的深度
- locals:局部变量所需的存储空间,以 Slot 为单位,4 个字节,注意 Slot 可以复用
- args_size:方法参数个数,包含有隐藏参数 this 在内
- LineNumberTable:描述源码行号与字节码行号(字节码偏移量)之间的对应关系
- LocalVariableTable:描述帧栈中局部变量与源码中定义的变量之间的关系
类加载过程:类加载通常包括加载,验证,准备,解析和初始化五个阶段,其中解析阶段可以在初始化之后开始,这是为了支持 Java 的动态绑定,其他四个阶段按照顺序开始,但不一定按顺序结束
- 加载:可以使用系统的类加载器,也可以使用自定义类加载器,并且允许加载器提前加载某个类
- 通过类的全限定名获取其二进制字节流
- 将字节流代表的静态结构转化为方法区的运行时数据结构
- 在堆区生成代表该类的 java.lang.Class 对象
- 连接:
- 验证:确保被加载的类的正确性,包括文件格式验证,元数据验证,字节码验证和符号引用验证
- 准备:为类的静态变量分配内存,并将其初始化为默认值,注意并不是在 Java 代码中被显式赋予的值,但是,如果是 ConstantValue(static final),则在准备阶段就会被赋值
- 解析:把类中的符号引用转换为直接引用
- 初始化:为类的静态变量赋予正确的值,只有当对类的主动使用的时候才会导致类的初始化
- 如果该类还没有加载和连接,则先加载并连接
- 如果该类的直接父类还没有初始化,则先初始化直接父类
- 如果类中有初始化语句,则依次执行初始化语句
类加载器划分:
- 启动类加载器:Bootstrap ClassLoader,负责加载存在 JDK\jre\lib 或者被 -Xbootclasspath 参数指定路径的类库
- 扩展类加载器:Extension ClassLoader,负责加载 JDK\jre\lib\ext 或者系统变量 java.ext.dirs 指定的所有类库
- 应用程序加载器:Application ClassLoader,负责加载用户路径(ClassPath)下指定的类库
类加载方式:
- 命令行启动时 JVM 初始化加载
- Class.forName:将字节码加载到 JVM 中,并且默认执行类的 static 块,可通过参数控制
- ClassLoader.loadClass:只会将字节码文件加载到 JVM 中
JVM 类加载机制:
- 全盘负责:当一个类加载器负责加载某个字节码时,其所依赖的和引用的字节码文件也将会交给该类加载器负责,除非显式指定
- 父类委托:先让父类试图加载该类,没有加载成功时,才尝试从自己的类路径中加载该类
- 缓存机制:保证所有加载过的字节码都会被缓存,这就是为什么修改了 Class 文件后,需要重启 JVM
- 双亲委派机制:将加载请求向上传播,只有当直接或者间接父类加载器无法加载时,才开始尝试加载
- 防止内存中出现多个同样的字节码
- 保证 Java 程序安全稳定的运行
自定义类加载器:继承自 ClassLoader,只需要重写 findClass 即可,注意不要重写 loadClass 方法,这样的话可能破坏双亲委派模式
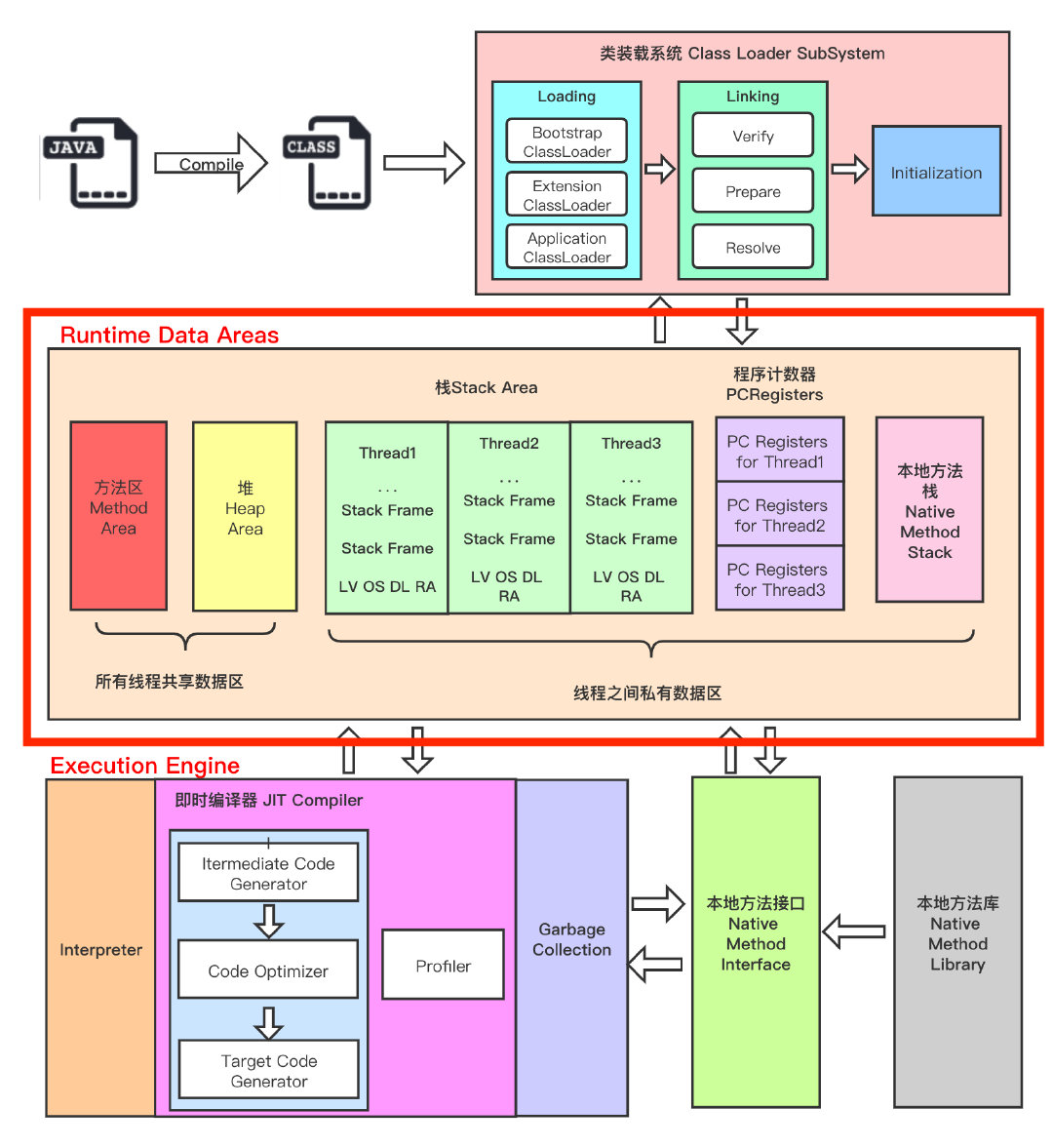
运行时数据区:规定了 Java 在运行过程中内存申请,分配,管理的策略,保证了 JVM 高效运行
- 线程私有:程序计数器,虚拟机栈,本地方法区
- 线程共享:堆,方法区,堆外内存(Java7 中的永久代或 Java8 中的元空间)
程序计数器:用来存储指向下一条指令的地址,如果执行的是 Java 方法,记录的是 JVM 字节码指令地址,如果是 native 方法,则是未指定值(undefined)
虚拟机栈:每个线程创建时都会创建一个虚拟机栈,内部保存有一个个栈帧,对应着一次次的 Java 方法调用,不存在垃圾回收问题
- 栈的基本单位:栈帧,表示每次 Java 方法调用,保存方法执行中的各种数据信息
- 栈运行原理:方法调用对应栈帧入栈,方法退出或者异常退出对应栈帧出栈
- 栈帧内部结构:
- 局部变量表:基本存储单元是 Slot,32 位,如果是对象方法,this 存储在 0 号 Slot 处,其余参数按照顺序继续排列,注意 Slot 可重用
- 操作数栈:根据字节码指令,往操作数栈中写入数据或者提取数据,JVM 虚拟机解释引擎是基于栈的,但是这样的话可能带来性能问题,HotSpot JVM 提出栈顶缓存技术,将栈顶元素全部缓存在物理 CPU 的寄存器中,以此降低对内存的读/写次数,提升执行引擎的执行效率
- 动态链接:将符号引用转换为调用方法的直接引用
- 非虚方法:如果方法在编译器就确定了具体的调用版本,并且该版本在运行时是不可变的,比如静态方法,私有方法,实例构造器,final 方法
- 虚方法:其他方法称为虚方法
- 方法返回地址:用来存放调用该方法的程序计数器的值
- 附加信息:携带与 Java 虚拟机实现相关的一些附加信息
本地方法栈:类似虚拟机栈,不过其用于管理本地方法的调用,本地方法就是 Java 调用非 Java 代码的接口,如 Unsafe 类中的本地方法,使用本地方法通常使用因为效率或者 Java 语言难以实现的问题,在 HotSpot JVM 中,直接将本地方法栈和虚拟机栈合二为一
堆内存:
内存划分:为了优化 GC 性能,逻辑上划分为三块内存
- 新生代:用于分配新对象和没到达一定年龄的对象,包括伊甸园(Eden Memory)和两个幸存区(Survivor Memory),默认比例 8:1:1,Minor GC 检查 Eden 空间和其中一个幸存区中的对象,并将他们移动到另一个幸存者空间
- 老年代:存放长时间使用的对象,也存储大对象,防止发生大量拷贝
- 元空间:Java8 之前称作是永久代, JDK8 及以后的元空间
设置堆内存大小:
-Xms设置堆的初始内存,-Xmx表示堆的最大内存,通常两者配置相同,保证 GC 完成后不需要再重新分割计算堆的大小,提高性能,-XX:+UseAdaptiveSizePolicy可以会动态调整 JVM 堆中各个区域的大小以及进入老年代的年龄TLAB:对 Eden 区继续划分,JVM 为每个线程分配了一个私有缓存区域
- 避免了多线程使用同一个地址,需要使用加锁机制,降低性能
- 能够提升内存分配的吞吐量
逃逸分析:能够有效减少同步负载和内存堆分配压力的跨函数全局数据流分析算法
- 栈上分配:如果对象没有逃逸,直接在栈上分配对象
- 同步省略:一个对象只有一个线程访问,则不需要同步
- 标量替换:将聚合量变为多个标量表示,而不会创建对象,降低消耗
逃逸分析带来的性能提升不一定高于其带来的性能消耗,其本身是一个相对耗时的过程
方法区:
方法区,永久代,元数据区:永久代和元数据区可以当作是方法区的落地实现
- 方法区是 JVM 规范定义的一个概念,用于存储类信息,常量池,静态变量等
- 永久代是 HotSpot 虚拟机特有的概念,和老年代地址空间连续,可以被 GC
- 元空间则是永久代的替换,存在于堆外内存,不受限于 GC
方法区内部结构:
- 类型信息:保存每个被加载类型(类,接口,枚举,注解)的信息
- 运行时常量池:保存类加载后的常量池表,也可以运行期间放入,如 String 类 intern 方法
- 域信息:保存所有域的相关信息以及域的声明顺序
- 方法信息:保存方法的相关信息
注意,HotSpot JVM 中类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中
方法区的垃圾回收:常量池中废弃的常量和不再使用的类型
Java 内存模型:JVM 通过栈独占,堆共享来划分内存,方法的基本类型局部变量和对象引用栈上分配,而对象则分配在堆上,当 JMM 和现代硬件内存连接时,会产生以下问题:
- 对象共享后的可见性:由于高速缓存的存在,更新后的值可能其他线程不能看到,使用 volatile
- 竟态条件:两个线程对共享对象都执行加一操作,结果实际上值只加一,使用 synchronized
并发编程模型:主要分为共享内存和消息传递,Java 采用共享内存实现线程之前的通信,但需要程序员的显式同步操作
重排序:为了提高程序执行时性能,JMM 对于处理器重排序,会在必要时生成内存屏障
- 编译器优化的重排序:调整语句的执行顺序
- 指令级并行的重排序:多个指令重叠执行
- 内存系统的重排序:调整加载和存储指令的顺序
内存屏障指令:用来禁止特定类型的处理器重排序,其中,StoreLoad 屏障同时具有其他三个屏障的效果,实现原理是处理器要把写缓冲的数据刷写到内存,开销较大
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 确保 Load1 数据的装载,之前于 Load2 及所有后续装载指令的装载。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 确保 Store1 数据对其他处理器可见(刷新到内存),之前于 Store2 及所有后续存储指令的存储。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 确保 Load1 数据装载,之前于 Store2 及所有后续的存储指令刷新到内存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 确保 Store1 数据对其他处理器变得可见(指刷新到内存),之前于 Load2 及所有后续装载指令的装载。 |
happens-before:用来阐述操作之间的内存可见性,a hanppens-before b 表示 a 操作的结果对 b 操作来说是可见的,其满足传递性
as-if-serial:不管怎么重排序,单线程执行的结果不能被改变
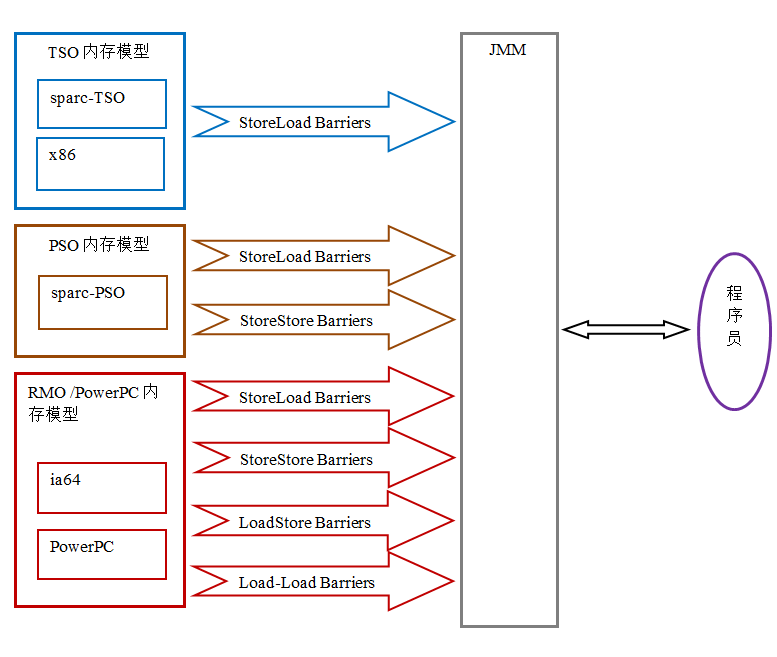
Java 内存模型:将顺序一致性模型做为参考,同时对不存在数据依赖性的操作进行重排序
- TSO(total store ordering):允许写-读操作的重排序
- PSO(partial store ordering):在 TSO 基础上,允许写-写操作的重排序
- RMO(elaxed memory ordering):在 TSO 基础上,放松程序中读 - 写和读 - 读操作的顺序
对象回收算法:
- 引用计数算法:给对象增加一个引用计数器,表示当前引用的个数,尽管使用 Recycler 算法可以解决循环引用的问题,但是其性能消耗难以预测
- 可达性分析:通过 GC Roots 做为起始点进行搜索,不可达的对象可被回收,JVM 中的 GC Roots
- 虚拟机栈中引用的对象
- 本地方法栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象
方法区的回收:主要存放永久代对象,对对象回收的效益不高,主要对常量池的回收和对类的卸载
finalize:类似析构函数,用于资源释放,但是 try-with-resources 方法更优,而且其执行时机是不确定的,可能还会由于自救机制导致对象不能回收
引用类型:不论是引用计数,还是可达性分析,都与引用相关
- 强引用:被强引用关联的对象不会被回收,new
- 软引用:被软引用关联的对象只有在内存不够的情况下才会被回收,SoftReference
- 弱引用:被弱引用关联的对象一定会被回收(下一次 GC 时),WeakReference
- 虚引用:一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,唯一目的是在该对象被回收的时候收到一个系统通知,PhantomReference
垃圾回收算法:
- 标记-清除:将存活的对象进行标记,然后清理掉未被标记的对象,碎片化现象严重
- 标记-整理:让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
- 标记-复制:划分内存大小为相同的两块,每次只使用其中一块,另一块用于下一次复制操作
- 分代收集:根据对象存活周期,采用不同的收集算法,新生代使用复制算法,老年代使用标记-清除或者标记-整理算法
垃圾回收器:
Serial 收集器和 Serial Old 收集器:前者新生代收集器,使用复制算法,后者老年代收集器,使用标记-整理算法
ParNew 收集器:是 Serial 收集器的多线程版本,是 Server 模式下的虚拟机首选新生代收集器
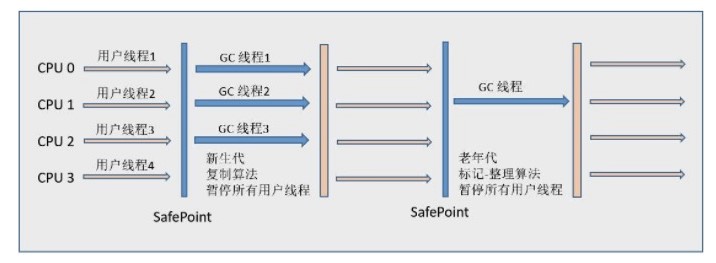
Parallel Scavenge 收集器和 Parallel Old 收集器:在注重吞吐量以及 CPU 资源敏感的场合可以使用
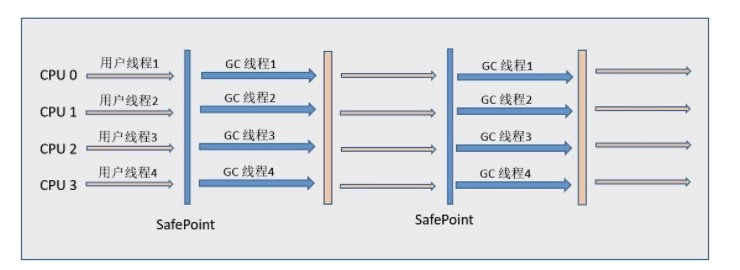
CMS(Concurrent Mark Sweep) 收集器:分为四个阶段,其中只有初始标记和重新标记需要 STW
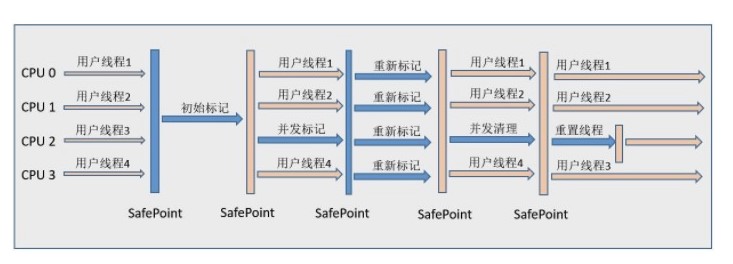
缺点:
- 吞吐量低:低停顿时间是以牺牲吞吐量为代价的
- 无法处理浮动垃圾,容易引发 Concurrent Mode Failure:浮动垃圾指的是并发清理阶段用户线程产生的垃圾,需要等到下一次 GC 才能被回收,由于浮动垃圾,需要预留出一部分的内存,如果不够,则出现 Concurrent Mode Failure
- 标记-清除容易导致空间碎片,大对象可能分配失败,因此需要提前触发 Full GC
G1(Garbage First) 收集器:面向服务端应用的垃圾收集器,开发目的用于替换 CMS 收集器。G1 可以直接对新生代和老年代一起回收,G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离,每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region,可达性分析的时候可以避免全堆扫描
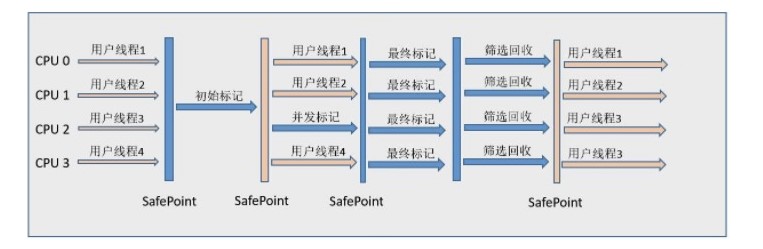
特点:
- 空间整合:整体上是基于标记-整理算法,局部(两个 region 之间)上基于复制算法
- 可预测的停顿
Epsilon 收集器:不执行任何垃圾回收动作的回收器,主要用作性能分析
回收策略:
- Minor GC:发生在新生代上,执行相对比较频繁
- 触发条件:Eden 空间满,就触发一次
- Major GC:发生在老年代上,较少执行
- 触发条件:
- 调用 System.gc:建议虚拟机执行 Major GC
- 老年代空间不足:大对象或者大数组创建
- 空间分配担保失败:使用复制算法的 Minor GC 需要老年代的内存空间作担保
- Concurrent Mode Failure
- 触发条件:
- Full GC:整个堆上的垃圾回收
G1 收集器:是一个分代的,增量的,并行与并发的标记-复制垃圾回收器,是为了适应现在不断扩大的内存和不断增加的处理器数量,进一步降低暂停时间(pause time),同时兼顾良好的吞吐量,相对于 CMS:
- G1 垃圾回收器是 compacting 的,回收得到的空间是连续的
- G1 回收器的内存模型是分块的,其将内存划分为一个个的 Region,Region 为回收的基本单位
- 软实时:用户可以指定垃圾回收时间的限时,G1 会努力但不保证在这个时限内完成垃圾回收
G1 内存模型:
- 分区概念:
- 分区 Region:将整个堆空间按照分区进行划分,分区可以按需在年轻代和老年代之间切换
- 卡片 Card:每个分区内部划分为一系列的 Card,标识可用分区的卡片将会被记录在全局卡片表中
- 堆 Heap:同样可以通过 -Xms/-Xmx 来指定堆空间大小
- 分代模型:
- 分代垃圾回收:可以将重点放在最近分配的对象上,而无需扫描整个堆空间,同样的,G1 采用了年轻代和老年代来划分,其中年轻代由 Eden,S1,S2 空间构成
- 本地分配缓冲:由于分区,每个线程可以认领某个分区用于线程本地的内存分配,减少了同步时间
- 分区模型:G1 对内存的使用以分区(Region)为单位,而对对象的分配则以卡片(Card)为单位
- 巨型对象:大小超过分区大小一半的对象,分配的时候直接在老年代分配,所占用的空间称为巨型分区(Humongous Region)
- 已记忆集合(Remember Set):为了避免 STW 式的整堆扫描,在每个分区记录了一个已记忆集合(RSet),内部类似一个反向指针,记录引用分区内对象的卡片索引,当回收该分区时,只需要遍历 RSet 内的卡片索引就可以了
- Per Region Table (PRT):Rset 需要占用部分空间,如果一个分区被引用的次数很多,可能需要大量空间保存卡片索引,为此,其内部使用的 PRT 提供三种粒度的记录:
- 稀少:直接记录引用对象的卡片索引
- 细粒度:记录引用对象的分区索引
- 粗粒度:只记录引用情况,每个分区对应一个比特位,需要遍历整个堆才能找到所有引用
- 收集集合(CSet):代表每次 GC 暂停时回收的一系列目标分区,在任意一次收集暂停中,CSet所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中
- 并发标记算法:使用的是三色标记法,白色是未标记;灰色自身被标记,引用的对象未标记;黑色自身与引用对象都已标记。最终黑色的对象是存活对象,白色的是垃圾
- 漏标问题:在标记过程中,如果发生白色对象被黑色对象引用,并且灰指向白引用的消失,此时白色对象可能被当作垃圾清理,可以通过:
- 跟踪黑指向白的增加(增量更新):关注引用的增加,把黑色重新标记为灰色,需要重新扫描属性,效率较低
- 记录灰指向白的消失(起始快照算法):当该引用删除时,将被引用对象推到 GC 的推栈,G1 采用该方法,因为其效率较高,不需要再次扫描
G1 活动周期:
垃圾活动周期图:
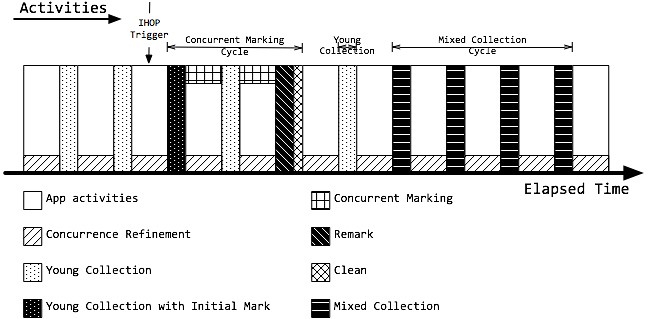
RSet 的维护:
- 栅栏 Barrier:
obj1.a = obj2,通过写前栅栏标记原来丧失引用的对象,通过写后栅栏更新新的被引用的对象所在分区,并不是每次栅栏操作后都需要更新 RSet,可以在 SATB 或者并发优化线程中批量执行 - 起始快照算法(SATB):在清理工作开始时创建堆的逻辑快照,从而确保所有垃圾对象被鉴别出来,写前栅栏会在引用变更前,将值记录在 SATB 日志中
- 并发优化线程(Concurrence Refinement Threads):写后栅栏会先通过 G1 的过滤技术判断是否是跨分区的引用更新,将跨分区更新对象的卡片加入缓冲区序列,即更新日志缓冲区或脏卡片队列
- 栅栏 Barrier:
并发标记周期:这个阶段将会为混合收集周期识别垃圾最多的老年代分区
- 初始标记:负责标记所有能被直接可达的根对象(原生栈对象、全局对象、JNI对象)
- 根分区扫描:为了保证标记算法的正确性,所有新复制到Survivor分区的对象,都需要被扫描并标记成根
- 并发标记:根据根对象,进行并发标记
- 重新标记:去处理剩下的 SATB 日志缓冲区和所有更新,找出所有未被访问的存活对象
收集类型:
- 年轻代收集:在年轻代满时,触发年轻代收集
- 混合收集周期:随着老年代内存增长,当到达IHOP阈值(老年代占整堆比,默认45%)时,G1开始着手准备收集老年代空间
ZGC:JDK11 中引入,适用于大内存低延迟服务的内存管理和回收,设计目标是
- 停顿时间不超过 10ms
- 停顿时间不会随着堆的大小,或者活跃对象的大小而增加
- 支持最高 4TB 级别的堆
CMS 和 G1 停顿分析:都使用了标记-复制算法,三个阶段中
- 标记阶段:初始标记阶段和再标记阶段是 STW,并发标记阶段不是 STW
- 清理阶段:清点出有存活对象的分区和没有存活对象的分区,该阶段是 STW
- 复制阶段:复制耗时和对象数量成正比,也是 STW
ZGC 原理:
全并发的 ZGC:采用标记-复制算法,不过在标记,复制和重定向阶段几乎都是并发的,只有初始标记,再标记和初始转移是 STW
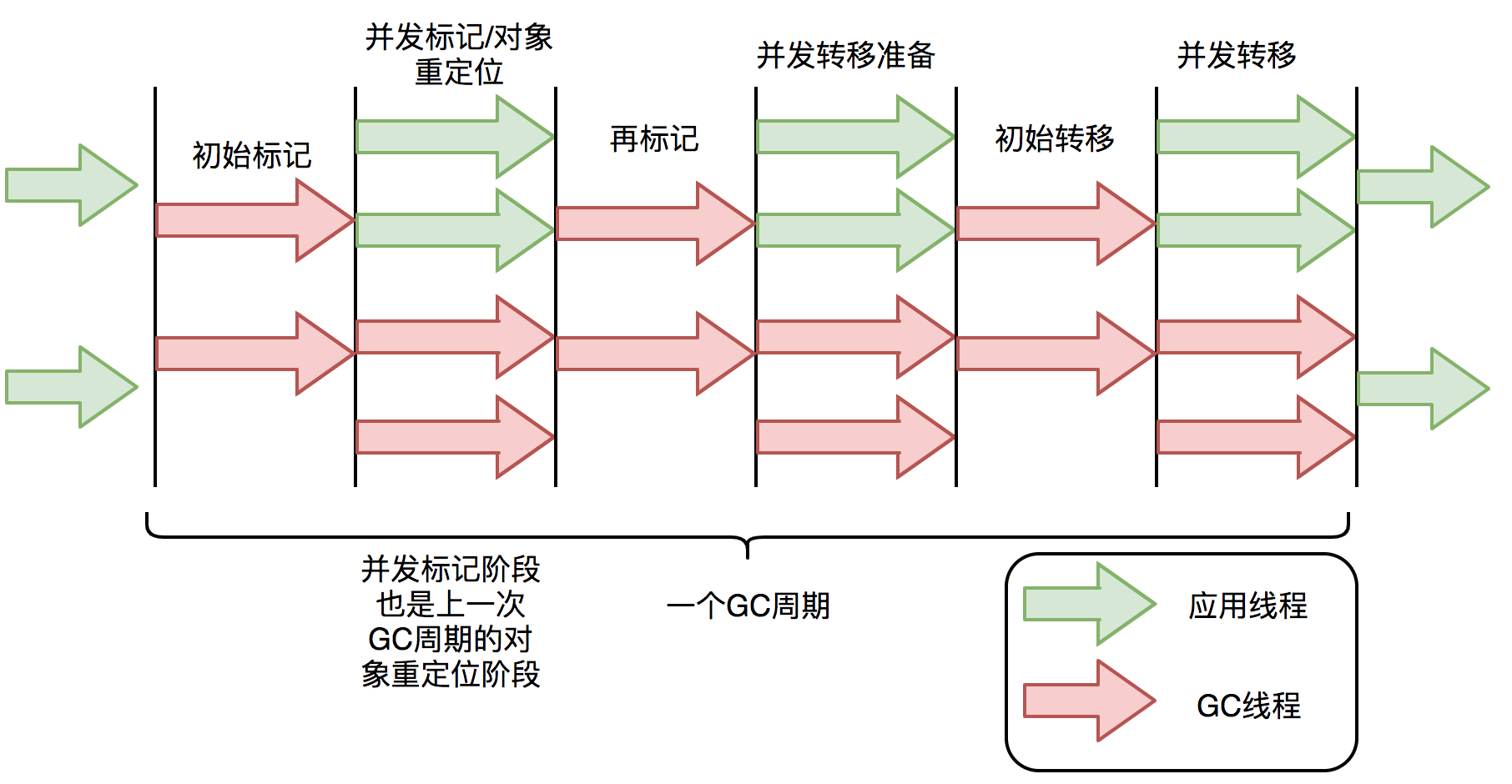
ZGC 关键技术:通过着色指针和读屏障技术,解决了转移过程中准确访问对象的问题,实现了并发转移
- 着色指针:将信息存储在指针中的技术,指针中第42~45位存储元数据,分别表示 Marked 0,Marked 1,Remapped,Finalized 信息
- 读屏障:当应用线程从堆中读取对象引用时,就会执行读屏障代码,其作用是在对象标记和转移过程中,用于确定对象的引用地址是否满足条件,并作出相应动作
ZGC 调优:
ZGC 调优参数:
1
2
3
4
5
6
7-Xms10G -Xmx10G
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/opt/logs/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50mZGC 触发时机:
- 阻塞内存分配请求触发:垃圾占满堆空间
- 基于分配速率的自适应算法:根据近期对象分配速率以及 GC 时间,计算下一次触发 GC 内存阈值
- 基于固定间隔:通过 ZCollectionInterval 控制,适合应对突增流量场景
- 主动触发规则:类似于固定间隔规则,但时间间隔不固定,是ZGC自行算出来的时机
- 预热规则:服务刚启动时出现,一般不需要关注
- 外部触发:代码中显式调用 System.gc() 触发
- 元数据分配触发:元数据区不足时导致,一般不需要关注
GC 考虑指标:
- 吞吐量:业务线程占用 CPU 的时间和系统总运行时间比例
- 停顿时间:垃圾收集过程中一次 STW 的最长时间,越短越好
JVM 常见调优参数:
- -Xms 和 -Xmx:堆初始值和堆最大值,通常设置相同,避免动态扩容的开销
- -Xmn:新生代大小
- -XX:newRatio:设置新生代与老年代比值
- -XX:SurvivorRatio:Eden 区与 Survivor 区大小的比值
- -XX:PermSize 和 -XX:MaxPermSize:永久代初始值和永久代最大值,Java7 参数
- -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize:元空间初始值和元空间最大值
- -XX:MaxTenuringThreshold:新生代转移到老年代的年龄阈值
- -XX:+AggressiveOpts:加快编译速度
- -XX:PretenureSizeThreshold:对象超过多大值时直接在老年代中分配
JVM 回收期参数:
- -XX:+UseSerialGC:串行垃圾回收,很少使用
- -XX:+UseParNewGC:新生代使用并行,老年代使用串行
- -XX:+UseConcMarkSweepGC:新生代使用并行,老年代使用 CMS
- -XX:ParallelGCThreads:指定并行的垃圾回收线程的数量
- -XX:+DisableExplicitGC:禁用 System.gc(),因为它会触发Full GC,这是很浪费性能的
- -XX:CMSFullGCsBeforeCompaction:在多少次 GC 后进行内存整理,减少碎片化
- -XX:+UseCMSCompactAtFullCollection:在每一次Full GC时对老年代区域碎片整理
- -XX:+CmsClassUnloadingEnabled:卸载类信息,也就是对永久带清理
- -XX:+PrintGCDetails 和 -XX:+PrintGCDateStamps:打印 GC 信息和时戳
内存溢出问题:
- 堆内存溢出:
- 堆内存溢出:大量创建对象,并且让 GC Roots 引用到它们
- 大量时间用于 GC,表示即将发生上类错误:98% 时间只回收了 2% 的垃圾
- 元空间区内存溢出:
- 不停加载类,导致元空间内存溢出
堆内存 dump 分析:
- 通过 OOM 获取:-XX:+HeapDumpOnOutOfMemoryError
- 主动获取:-XX:+HeapDumpOnCtrlBreak
- 使用 HPROF agent:-agentlib:hprof=heap=dump,format=b,在结束时生成 Dump 文件
- jmap 获取:
jmap -dump:format=b file=<文件名XX.hprof> <pid> - 堆内存分析:JConsole 和 Jprofile
Thread Dump 分析:诊断 Java 应用问题的工具,提供了当前活动线程的快照,以及 JVM 中所有 Java 线程的堆栈跟踪信息
Thread Dump 抓取:
jps && jstack [-l] <pid> | tee -a jstack.log
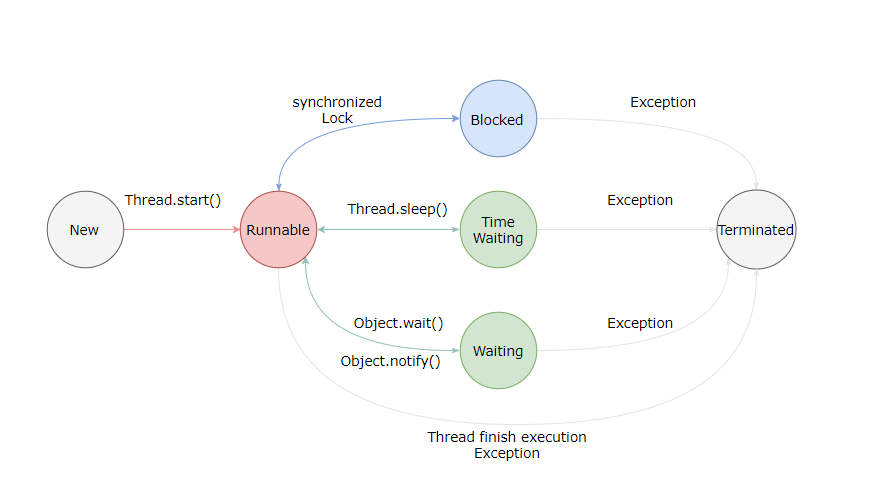
Thread 状态分析:
- NEW:刚刚在堆中创建 Thread 对象,但是没有调用 start 方法前
- RUNNABLE:该状态表示线程具备所有运行条件,在运行队列中准备操作系统的调度,或者正在运行
- BLOCKED:线程正在等待获取 java 对象的监视器,即线程正在等待进入由 synchronized 代码块
- WAITING:只有特定的条件满足,才能获得执行机会,如 Object.wait
- TIMED_WAITING:定时器等待
- TERMINATED:执行完 run 方法正常返回,或者抛出了运行时异常而结束
异常情况:
- 死锁:表现为程序的停顿,或者不再响应用户的请求,线程 dump 中可以直接报告出 Java 级别的死锁
- 热锁:往往是导致系统性能瓶颈的主要因素,表现为由于多个线程对临界区,或者锁的竞争,出现
- 频繁的线程的上下文切换
- 大量的系统调用
- 随着CPU数目的增多,系统的性能反而下降
Java 问题排查工具:
- Linux 命令
- 文本操作:grep,awk,sed
- 文件操作:tail,find
- 网络和进程:ifconfig,iptables,route,netstat,ps,top
- 磁盘和内存:free,df,du,/proc/meminfo,fdisk,swapon,swapoff
- 用户和组:w,id,last,cut -d: -f1 /etc/passwd
- 服务模块和包:crontab -l,lsmod
- 系统版本信息:uptime,uname,procfs
- Java 工具
- jps:获取当前 java 进程的工具
- jstack:线程堆栈分析工具,导出 Java 应用程序线程堆栈信息
- jinfo:用来查看正在运行的 java 应用程序的扩展参数,也可以动态的修改正在运行的 JVM 参数
- jmap:可以生成 java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息
- jstat:输出进程的统计信息
- jdb:可以远程 debug
- btrace:可以在运行中的java类中动态的注入trace代码,在不停机下得到方法参数,返回值,起到监控作用
- Greys:用来分析运行中的java类、方法等信息
- Arthas:在线调试,基于 Greys
- javOSize:可以修改字节码,并且即时生效,但是侵入性太大
- 可视化工具:
- JConsole:自带的基于 JMX 的可视化监视、管理工具
- Visual VM:免费的,集成了多个 JDK 命令行工具的可视化工具,它能为您提供强大的分析能力,对 Java 应用程序做性能分析和调优
- Visual GC:visualvm 中的图形化查看 gc 状况的插件
- JProfiler:通过实时的监控系统的内存使用情况,随时监视垃圾回收,线程运行状况等手段,从而很好的监视 JVM 运行情况及其性能
- Eclipse Memory Analyzer (MAT):快速且功能丰富的 Java 堆分析器,可帮助你发现内存泄漏并减少内存消耗
11 多线程和并发
并发出现问题的根源:
- 可见性:CPU 缓存引起
- 原子性:分时复用引起
- 有序性:重排序引起
使用 JMM 解决并发问题:
- 三个关键字:volatile,synchronized,final
- Happens-Before 规则
线程安全级别:
- 不可变:不可变对象一定是线程安全的,不需要再采取任何线程安全保障措施,包括:
- final 关键字修饰的基本数据类型
- String
- 枚举类型
- Number 部分子类,如 Long 和 Double 等包装类型,BigInteger 和 BigDecimal 等大数据类型
- 对集合,可以使用 Collections.unmodifiableXXX() 来获取一个不可变集合
- 绝对线程安全:不管运行时环境如何,调用者都不需要任何额外的同步措施
- 相对线程安全:单独操作时候,不需要额外的同步措施,但是对一些特定顺序的连续调用,需要在调用段使用额外的同步手段,包括 Vector、HashTable、Collections 的 synchronizedCollection() 方法包装的集合
- 线程兼容:对象本身不是线程安全的,可以在调用端正确使用同步手段安全使用,如 ArrayList 和HashMap 等
- 线程对立:无论是否在调用段采取了同步措施,都无法在多线程环境中并发安全使用的代码
线程安全实现:
- 互斥同步:synchronized 和 ReentrantLock,线程阻塞和唤醒可能带来性能问题,悲观并发策略
- 非阻塞同步:
- CAS:乐观并发控制,先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施,如不断重试。硬件支持,CAS 指令包括三个操作数,内存地址 V、旧的预期值 A 和新值 B,当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B
- AtomicInteger:使用了 Unsafe 类的 CAS 操作封装而成
- ABA 问题:如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过吗,该问题可以通过 AtomicStampedReference 来解决
- 无同步方案:
- 栈封闭:如局部基本类型变量,属于线程私有
- 线程本地存储:使用 ThreadLocal 类实现,底层实现是每个 Thread 都有一个 ThreadLocalMap
- 可重入代码:在代码执行的任何时刻中断它,转而去执行另外一段代码,在控制权返回后,原来的程序不会出现任何错误
线程状态转换:
线程使用方式:实现接口或者继承 Thread,推荐使用实现接口方案
- 实现 Runnable 接口:实现 run 方法
- 实现 Callable 接口:实现 带有返回值的 call 方法
- 继承 Thread 类:同样实现 run 方法,其实现了 Runnable 接口
基础线程机制:
- Executor:管理多个异步任务的执行,此处异步表示不需要同步操作
- CachedThreadPool:一个任务一个线程
- FixedThreadPool:所有任务使用固定数量的线程
- SingleThreadExecutor: 相当于大小为 1 的 FixedThreadPool
- Daemon:守护线程,是程序运行时在后台提供服务的线程,当所有非守护线程结束时,程序终止,同时杀死所有守护线程,main() 属于给守护线程,使用 setDaemon 设置某个线程为守护线程
- sleep:休眠当前正在执行的线程
- yield:声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行,只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行
线程中断:
- InterruptedException:使用 interrupt 来中断线程,如果线程处于阻塞,等待状态,就会抛出该异常而提前结束,但是不能中断 IO 阻塞和 synchronized 锁阻塞
- interrupted:如果线程一直运行一个循环,那么 interrupt 并不会导致其提前结束,可以通过 interrupted 方法检测线程是否被中断过,从而自己合理响应中断
- Executor 中断操作:shutdown 会等待所有线程执行完毕后再关闭,但是 shutdownNow 则直接调用每个线程的 interrupt 方法,另外,如果只想中断其中某个线程,可以使用 submit 方法得到 Future<?> 对象,然后调用其 cancel 方法中断
线程互斥同步:
- synchronized:JVM 实现
- 同步代码块:自定义同步对象
- 同步实例方法:作用于同一个对象实例
- 同步静态方法:作用于同一个类
- 同步一个类:作用于同一个类
- ReentrantLock:JDK 实现,主要通过 lock 和 unlock 实现同步
- 比较:
- 实现方式:synchronized 是 JVM 实现,ReentrantLock 是 JDK 实现
- 性能:新版本对 synchronized 进行了很多优化,两者大致相同
- 等待可中断:ReentrantLock 可以,但是 synchronized 不行
- 公平锁:默认非公平,但是 ReentrantLock 可以配置为公平的
- 锁绑定条件:一个 ReentrantLock 可以同时绑定多个 Condition 对象
- 使用:优先使用 synchronized, 除非需要 ReentrantLock 的高级功能,使用 synchronized 所有版本支持,并且不用担心没有释放锁而导致死锁问题
线程协作:
- join:在线程中调用另一个线程的 join 方法,会将当前线程挂起,直到目标线程结束
- wait & notify & notifyAll:属于 Object 一部分,只能在同步方法或者代码块中使用,并且在 wait 期间,线程会释放锁,否则可能会造成死锁
- await & signal & signalAll:Condition 一部分,相较于 wait,await 可以指定等待的条件,更加灵活
synchronized 使用:
- 一把锁只能被一个线程获取,没有获取的线程进入阻塞状态
- 每个实例对应自己的一把锁,不同实例之间互不影响,锁对象是 *.class 和修饰类方法除外
- 修饰方法时,无论是正常退出还是抛出异常,都会释放锁
synchronized 实现原理:
对象在堆中的结构:对象头 + 实例变量 + 填充数据,JVM 采用两个字来记录对象头信息,如果是数组,则还有一个字用于储存数据的长度
Class Metadata Address:类型指针指向对象的类数据
Mark Word:存储对象的 hashcode,锁信息或分代年龄或 GC 标志等信息,无锁状态 001 结尾
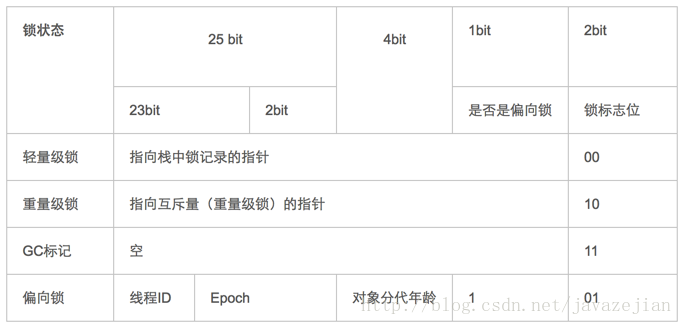
字节码实现:主要通过
monitorenter和monitorexit实现,并且字节码中还额外注入一条monitorexit指令,用于异常时能够释放 monitor 的所有权,每个对象都关联了一个 monitor 对象可重入原理:在同一锁程中,线程不需要再次获取同一把锁,直接将 monitor 中计数器加一即可
JVM 锁优化:
- 锁粗化:减少不必要的连续的 unlock 和 lock 操作,将多个小范围的锁扩展成更大的锁
- 锁消除:通过 JIT 逃逸分析判断出并不需要同步的操作
- 轻量级锁:使用 CAS 来进行锁的获取和释放,失败则阻塞
- 偏向锁:为了在无锁情况下执行 CAS 带来的开销
- 适应性自旋:当线程在轻量级锁执行 CAS 操作失败时,在进入重量级锁前会忙等待一段时间
锁膨胀方向:无锁 → 偏向锁 → 轻量级锁 → 重量级锁 (此过程是不可逆的)
轻量级锁实现:在执行同步块前,JVM 会在栈帧里面创建一个 Lock Record 空间,用于存储锁对象目前的 Mark Word 拷贝,然后,虚拟机使用 CAS 操作将标记字段 Mark Word 拷贝到锁记录中,并且将 Mark Word 更新为指向 Lock Record 的指针,并且更新对象的锁标志位,如果 CAS 操作失败,则锁膨胀
偏向锁:大多数环境下,锁只由同一个线程多次获取,反复加锁和释放锁可能带来性能消耗。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程 ID,以后该线程在进入和推出同步块时不需要进行 CAS 操作来加锁和解锁
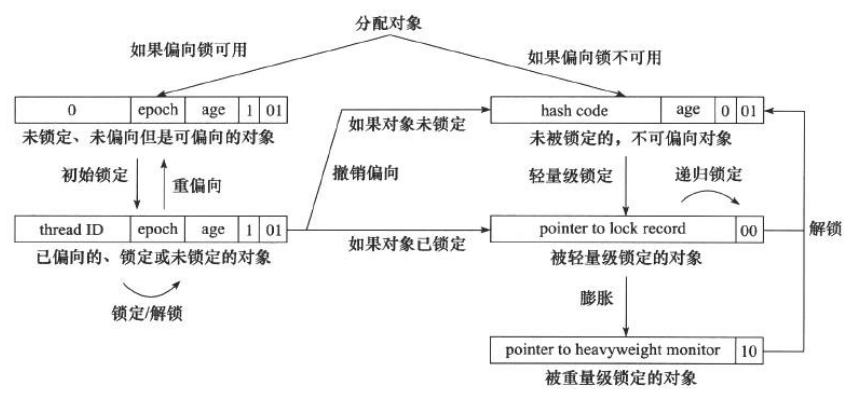
锁的优缺点对比:
| 锁 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要CAS操作,没有额外的性能消耗,和执行非同步方法相比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块的场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了响应速度 | 如线程成始终得不到锁竞争的线程,使用自旋会消耗CPU性能 | 追求响应时间,同步块执行速度非常快 |
| 重量级锁 | 线程竞争不适用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢,在多线程下,频繁的获取释放锁,会带来巨大的性能消耗 | 追求吞吐量,同步块执行速度较长 |
volatile 作用:
- 防止重排序:单例模式中的双重检查加锁(DCL)
- 实现可见性:防止 CPU 缓存造成线程不可见
- 保证单次读写的原子性:i++ 并不是原子性操作;共享 long 和 double 型变量时,需要使用 volatile
volatile 实现原理:
- 可见性实现:基于内存屏障实现,起作用就是防止编译器和 CPU 对该条内存屏障指令重排序
- lock 指令:对 volatile 变量写操作后,JVM 插入的指令,用于将缓存中的数据写到内存
- 缓存一致性:由于缓存的存在,使用 MESI 机制保证缓存一致性,其机制是利用了总线嗅探协议
- 有序性实现:
- volatile 的 happens-before 关系
- 禁止重排序:JMM 采用保守策略来为每个 volatile 读写操作添加不同屏障
- 对于 volatile 写操作,在其前面加入 StoreStore 屏障,在其后面加入 StoreLoad 屏障
- 对于 volatile 读操作,在其后面依次加上 LoadLoad 屏障和 LoadStore 屏障
volatile 应用场景:
- 状态标志:用于指示发生了某个一次性事件
- 独立观察:单个写多个读情况
- volatile bean 模式:JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 必须普通
- 双重检查:单例模式 DCL
final 基础使用:
- 修饰类:表示该类不可被继承,可以通过组合关系实现扩展性,注意
- final 类中的所有方法都为隐式 final
- 修饰方法:表示该类不可被子类重写,注意
- private 方法是隐式的 final 方法
- final 方法可以被重载
- 修饰参数:无法在方法中更改参数引用指向的对象,用于匿名类中传输数据
- 修饰变量:不一定是编译器常量,只是在被初始化后其值无法被更改
- static final:必须在定义的时候进行赋值
- blank final:必须在构造器中进行赋值
final 域重排序:
- 基本数据类型:
- final 域写:禁止 final 域写重排序到构造方法之外,从而保证该对象对所有线程可见时,final 域全部被初始化完毕,构造函数返回前插入 StoreStore
- final 域读:禁止初次读对象的引用与读该对象包含的 final 域的重排序,读操作前插入 LoadLoad
- 引用数据类型:
- 额外增加约束:禁止在构造函数对一个 final 修饰的对象的成员域的写入与随后将这个被构造的对象的引用赋值给引用变量重排序
final 深入理解:
- 对于存在 final 域初始化的构造函数中,不能让对象引用提前冲构造器中逃逸出去
- final 对象引用只是表示引用不变,对象本身还是可变的
- 使用 final 将禁止 JVM 进行自动类型转换,如两个 byte 相加和两个 final byte 相加
CAS 问题:CAS 基于乐观锁,synchronized 为悲观锁,通常 CAS 性能更优,但是其存在以下问题:
- ABA 问题:CAS 检测不到变化,但实际上发生了变化,使用 AtomicStampedReference
- 循环时间开销大:自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销
- 只能保证一个共享变量的原子操作:使用对象保证多个变量的原子性,使用 AtomicReference
Unsafe 类:Java 原子类通过 Unsafe 实现,其主要提供一些用于执行低级别、不安全操作的方法,这些方法在提升 Java 运行效率、增强 Java 语言底层资源操作能力方面起到了很大的作用,但是使用 Unsafe 类方法会使得 Java 语言不再安全,应该慎用 Unsafe 类
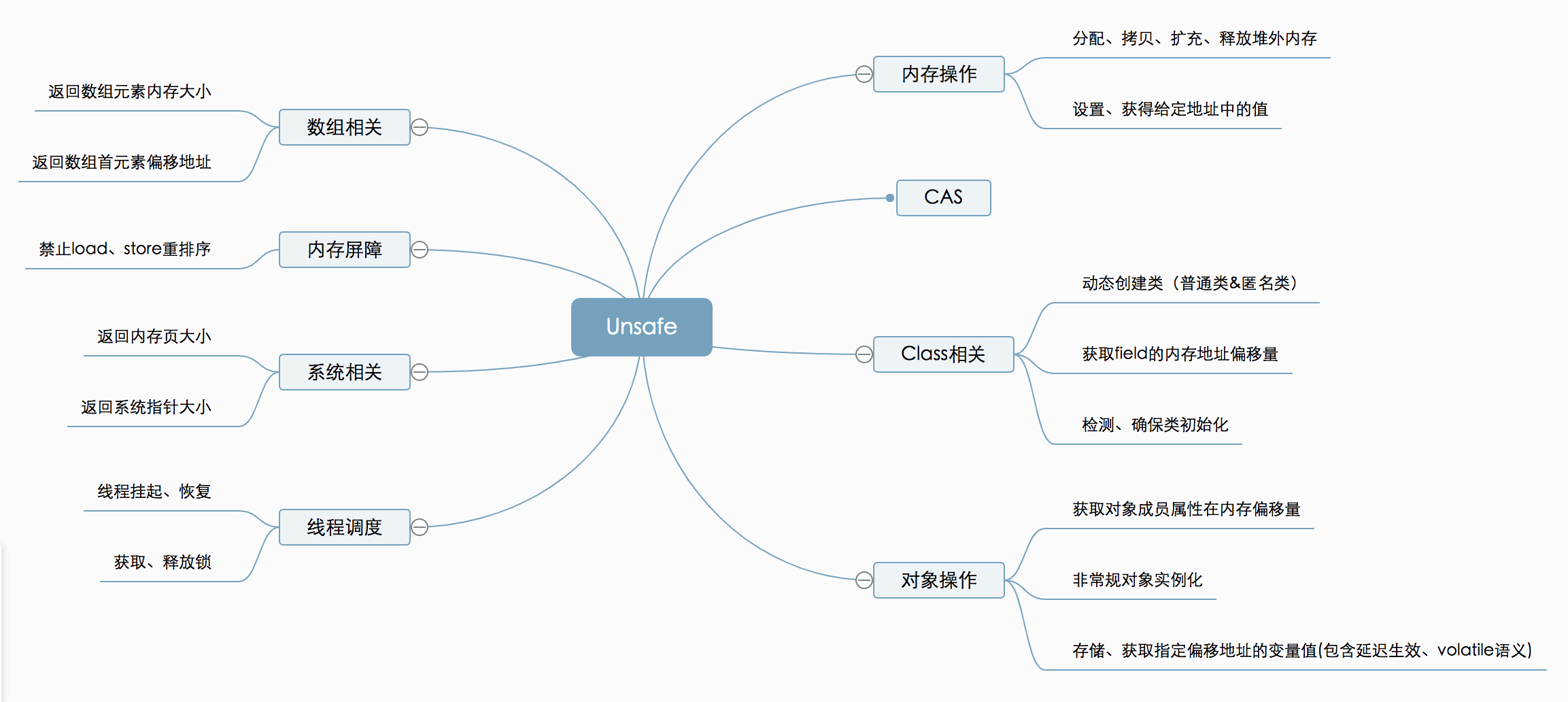
Unsafe 类部分功能:
- CAS:实际上只提供了三种 CAS 本地方法:
compareAndSwap{Object, Int, Long} - 提供域偏移量:staticFieldOffset
- 内存操作:allocateMemory & reallocateMemory & freeMemory
Java 中原子类:实现方式基于 volatile 和 Unsafe 中的 CAS 方法,前者保证可见性,后者保证原子性
- 原子更新基本类型:
Atomic{Boolean, Integer, Long} - 原子更新数组:
Atomic{Integer, Long, Reference}Array - 原子更新引用类型:
AtomicReference, Atomic{Stamped, Markable}Reference - 原子更新字段类:
Atomic{Integer, Long, Stamped, Reference}FieldUpdater
LockSupport:用于创建锁和其他同步类的基本线程阻塞原语,基于 Unsafe 类中的 park & unpark,相当于只有一个许可证的 Semaphore
- park:线程会阻塞,直到以下情况发生
- 其他线程将当前线程作为参数调用 unpark
- 其他线程中断当前线程
- 该调用毫无理由的返回
- unpark:将等待获得许可的线程作为参数,好让参数线程继续运行
线程同步分析:
- sleep 和 wait 区别:sleep 不会释放锁,wait 会释放锁,当从 wait 状态唤醒时,还是需要进行锁的获取,如果没有获取到,线程进入阻塞状态
- wait 和 await 区别:原理基本一致,且都释放锁资源,不过 await 底层通过 park 来阻塞线程
- sleep 和 park 区别:都是阻塞当前线程执行,且都不释放占有的锁资源,不过 park 可以主动被唤醒
- wait 和 park 区别:
- wait 需要在 synchronized 块中执行,park 可以在任何地方
- wait 被唤醒后不一定立即执行后续内容,因为需要获取锁,park 唤醒后则会继续执行后续内容
- wait & notify 和 park & unpark:前者必须先 wait 再 notify,否则一直等待,后者则不用
AQS(AbstractQueuedSynchronizer):一个用来构建锁和同步器的框架,对资源共享方式:
- 独占:只有一个线程能执行,如 ReentrantLock,还可以分为:
- 公平锁:按照 FIFO 规则依次获取锁资源
- 非公平锁:当线程要获取锁时,无视队列规则直接去抢锁
- 共享:多个线程可同时执行,如 Semaphore/CountDownLock
扩展 AQS:AQS 使用了模板方法设计模式,继承者只需要实现以下方法即可
- tryAcquire & tryRelease
- tryAcquireShared & tryReleaseShared
- isHeldExclusively
AQS 数据结构:
- sync queue:CLH 实现的双向链表
- Node:表示每个被封装的线程,每个节点都有一个状态:
CANCELLED,值为 1,表示当前的线程被取消SIGNAL,值为 -1,表示当前节点的后继节点包含的线程需要运行,需要进行 unpark 操作CONDITION,值为 -2,表示当前节点在等待 condition,也就是在 condition queue 中PROPAGATE,值为 -3,表示当前场景下后续的 acquireShared 能够得以执行- 值为0,表示当前节点在 sync queue 中,等待着获取锁
- Node:表示每个被封装的线程,每个节点都有一个状态:
- condition queue:单向链表实现
AQS 核心方法:
- acquire:以独占模式获取资源,并且忽略中断
- tryAcquire 方法如果失败,则将该线程封装线程添加到 sync queue 中,其中,enq 方法会使用无限循环来确保节点的成功插入
- acquireQueued 方法则是让 sync queue 中的第二个节点尝试获取资源,如果失败,则自旋等待
- release:如果头节点不为空,则 unparkSuccessor
AQS 总结:
- AQS 通过一个 int 同步状态码,和一个 FIFO 队列来控制多个线程访问资源
- 支持独占和共享两种模式获取同步状态码
- 当线程获取同步状态失败会被加入到同步队列中
- 当线程释放同步状态,会唤醒后继节点来获取同步状态
- 共享模式下的节点获取到同步状态或者释放同步状态时,不仅会唤醒后继节点,还会向后传播,唤醒所有同步节点
- 使用 volatile 关键字保证状态码在线程间的可见性,CAS 操作保证修改状态码过程的原子性
ReentrantLock 源码分析:
- 接口实现:实现了 Lock 接口,定义了 lock 和 unlock 相关操作,并且存在 newCondition 方法
- 三个内部类:
- Sync:继承自 AQS,未实现 lock 算法
- NonfairSync & FairSync:继承自 Sync,分别实现非公平锁和公平锁
- 锁控制:对该类的操作大部分直接转换为对 Sync 类的操作
- 可重入性:获取独占资源的线程,可以重复获取该独占资源,实现上通过计数器加一即可
ReentrantLock 和 synchronized 对比:
- 底层实现上:ReentrantLock 是 JDK 提供的,synchronized 是 JVM 提供的
- 手动释放:前者需要手动释放,最好配合 try-finally,后者不需要自己释放
- 是否可中断:前者可以通过 lockInterruptibly 响应中断,后者不可中断
- 是否公平锁:前者可以是公平锁,后者不是公平锁
- 是否可绑定 Condition:前者可以绑定 Condition 结合 await/signal 实现线程精确唤醒,后者则不行
ReentrantReadWriteLock 源码分析:
- 接口实现:实现了 ReadWriteLock 接口
- 类的内部类:
- Sync:继承自 AQS,使用一个 int 表示写锁(16bit)和读锁(16bit)数量,存在以下两个内部类
- HoldCounter:和读锁配套使用
- ThreadLocalHoldCounter:和写锁配套使用
- NonfairSync & FairSync:继承自 Sync,分别实现非公平锁和公平锁
- ReadLock & WriteLock:实现了 Lock 接口
- Sync:继承自 AQS,使用一个 int 表示写锁(16bit)和读锁(16bit)数量,存在以下两个内部类
- 类属性:同步队列 sync 和两个锁资源 readLock & wirteLock
ReentrantReadWriteLock.Sync 关键方法:
- tryRelease:用于尝试释放写锁资源,若释放后资源数量(state)为 0,则成功释放该锁
- tryAcquire:用于尝试获取写锁资源,如果当前资源数量(state)为 0,则成功获取,根据公平策略判断其是否会阻塞
- tryReleaseShared:用于尝试释放读锁资源,使用无限循环保证释放成功
- tryAcquireShared:用于尝试获取读锁资源,若存在写锁,则失败,否则,判断读线程是否需要被阻塞,若之前没有读锁,还需要设置第一个读线程 firstReader 和 firstReaderHoldCount
锁升降级:
- 锁降级:线程把持住(当前拥有的)写锁,再获取到读锁,随后释放(先前拥有的)写锁的过程
- 锁升级:RentrantReadWriteLock 不支持锁升级,目的是为了保证数据的可见性
HashTable:利用 synchronized 对 put 等操作进行加锁,从而加锁期间锁住的是整个哈希表,效率低下
ConcurrentHashMap - JDK7:使用分段锁机制实现,从而保证了并发度的提升
数据结构:整个 ConcurrentHashMap 由一组 Segment 组成,其通过继承 ReentrantLock 来加锁,外部 ConcurrentHashMap 的并发度由 concurrencyLevel 确定,实际上就是 Segement 的个数
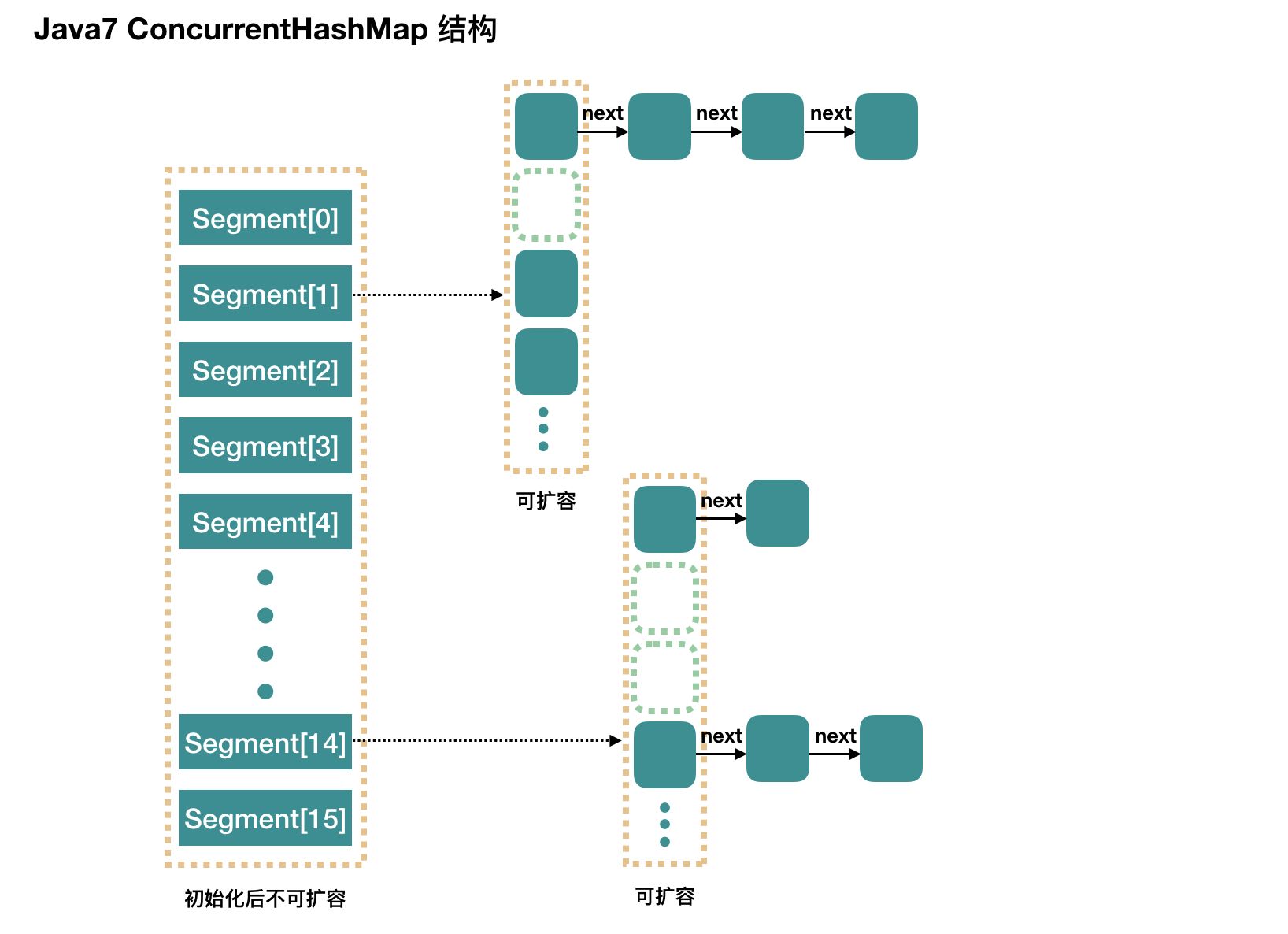
put 操作:
- 根据 hash 值找到对应的 segment
- segment 内部首先尝试获取锁资源,获取成功后进行 put 操作
get 操作:
- 计算 hash 值,找到对应的 segment
- 根据 hash 找到该 segment 内部数组对应的位置
- 根据链表顺序查找
ConcurrentHashMap - JDK8:
- 数据结构:实现上选择和 HashMap 类似的数组 + 链表 + 红黑树的方式,而加锁采用 CAS 和 synchronized 实现,并发度相较于 JDK7 上升
CopyOnWriteArrayList:
- 概述:是 ArrayList 的一个线程安全的变体,其中所有可变操作)都是通过对底层数组进行一次新的拷贝来实现的,使用 lock 保证并发安全性
- 实现关系:实现了 List,RandomAccess,Clonable 接口
- 内部类:COWIterator,其存在一个 Object 类型的数组作为 CopyOnWriteArrayList 数组的快照,因此,在创建迭代器后,迭代器就不会反映列表的修改,同时,在迭代器上不支持修改操作
- 类属性:lock 字段用于保证线程安全访问,还有一个 Object 数组,用来存放具体元素,使用反射机制和 CAS 来原子更新 lock 字段
- 基于数组拷贝实现:add & addIfAbsent & set & remove
- 缺陷:
- 由于写操作的时候,需要拷贝数据,可能会导致 young gc 或者 full gc
- 不能用于实时读的场景,因为拷贝数据本身需要时间,其能保持最终一致性,但是没法满足实时性
- 使用场景:合适读多写少的场景,但是慎用,因为不知道里面到底放置了多少数据
- 和 Vector 的比较:尽管 Vector 里面的每个方法都是同步的,但是使用上还需要额外在外层加上一层锁,双重锁会导致性能大幅降低,如 size && remove && remove(size - 1),第一个线程第二次 remove 时会出现错误,可以使用 CopyOnWriteArrayList 来代替 Vector
ConcurrentLinkedQueue:
- 简介:基于链接节点的无界线程安全队列,排序规则基于 FIFO,不允许插入 null 元素
- 数据结构:
- 内部类 Node(item, next),其通过 CAS 和反射机制来原子更新 item 和 next
- 包含 head 和 tail 的属性,表示头尾节点,但是其并不是表示队列的第一个元素或者最后一个元素,因为延迟更新的存在,head 可能是之前的第一个节点,但是已经被移除,tail 可能是最后一个节点的前一个节点
- 核心函数:
- offer:采用无限循环确保数据被插入到队列中,并且需要判断 tail 是否指向最后一个节点,如果不是,此时插入后还需要更新 tail 节点值
- poll:同样采用无限循环保证操作被正确进行,如果 head 的下一个节点为空,则需要更新 head 节点
- 非阻塞:当队列为空时,poll 将直接返回 null 而不会阻塞
- 延迟更新:只有当 head 和 tail 距离真正的第一个有效节点和最后一个有效节点大于等于 2 时才会更新,这样带来的好处是减少了 CAS 更新的操作,大大提升了操作效率,缺点是代码复杂性增大
- 使用场景:通过无锁实现了更高的并发量,是一个高性能的队列,但是使用场景没有阻塞队列常见,其通常使用在并发量特别大的情况下
BlockingQueue & BlockingDeque:
简介:阻塞队列和双向阻塞队列接口,适用于生常-消费场景
方法:不同操作方法处理异常的情况不同
抛异常 特定值 阻塞 超时 插入 add(o) offer(o) put(o) offer(o, timeout, timeunit) 移除 remove(o) poll(o) take(o) poll(timeout, timeunit) 检查 element(o) peek(o) 实现类:
- ArrayBlockingQueue:有界阻塞队列,并不会自动扩容
- DelayQueue:无界阻塞队列,用于放置实现了 Delayed 接口的对象,其中的对象只有在其到期时才能从队列中取走,常见使用如关闭空闲连接,缓存等
- LinkedBlockingQueue:链阻塞队列,不定义长度时为 Integer.MAX_VALUE
- SynchronousQueue:内部只能容纳单个元素
- PriorityBlockingQueue:无界的优先阻塞队列
- LinkedBlockingDeque:双向链阻塞队列
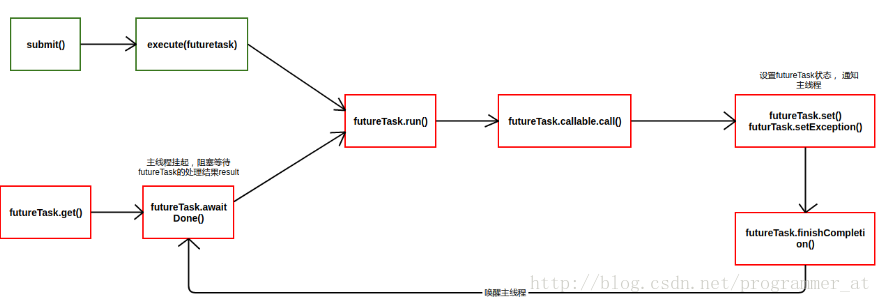
FutureTask:
简介:为 Future 提供了基础实现,如异步获取任务的执行结果和取消任务等,使用 CAS 确保线程安全
Future 接口:通过该接口可以查看任务是否执行完成,获取执行结果或者取消执行
状态转换:
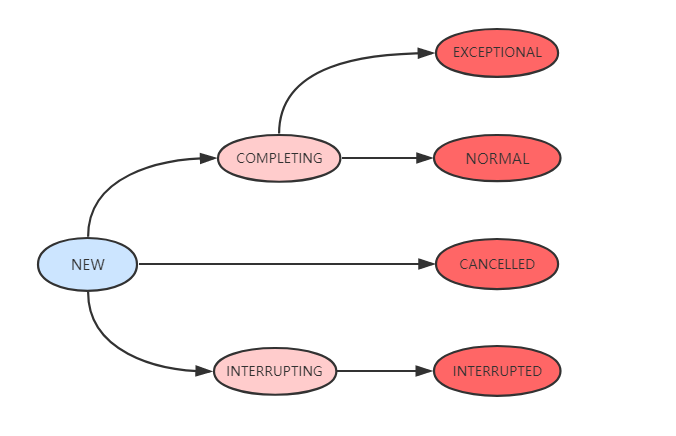
核心方法:
- run:如果任务状态是 NEW,则利用 CAS 修改线程为当前线程,执行完毕调用 set(result) 设置执行结果
- get:如果任务完成,直接返回结果,否则的话则进行等待,见当前线程加入 waiters 节点中
- cancel:尝试取消当前任务,如果任务已经完成或者取消,操作失败
使用:
- Future + ExecutorService
- FutureTask + ExecutorService
- FutureTask + Thread
ThreadPoolExecutor:
简介:线程池能够对线程统一分配,调优和监控,能够提高线程的可管理性。本身实现上就是一个线程集合 workerSet 和一个阻塞队列 workQueue,workerSet 里面的线程在空闲时不断从 workQueue 里面获取任务执行,没有任务时则会阻塞
原理:构造方法如下
1
2
3
4
5
6public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)- corePoolSize:每次提交一个任务时,都会创建一个线程用来处理该任务,直到线程数为 corePoolSize,当达到该值时,此时新任务会被放到阻塞队列中
- maximumPoolSize:当阻塞队列满并且有新任务时,则创建新线程执行任务,直到达到 maximumPoolSize
- keepAliveTime:线程空闲时的存活时间,只有在线程数大于 corePoolSize 时有效
- workQueue:用来保存等待被执行的任务的阻塞队列,可以是有界或者无界的
- handler:自定义的线程池的饱和策略,即当阻塞队列满并且没有空闲线程时,采取的处理策略
AbortPolicy:默认策略,直接抛出异常CallerRunsPolicy: 用调用者所在的线程来执行任务DiscardOldestPolicy: 丢弃阻塞队列中靠最前的任务,并执行当前任务DiscardPolicy: 直接丢弃任务
Executors 提供的三种策略:
newFixedThreadPool:饱和策略失效,并且 keepAliveTime 失效
1
2
3
4
5public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}newSingleThreadExecutor:和 newFixedThreadPool 相同,不过只有单个线程
newCachedThreadPool:可能会导致线程数过大
1
2
3
4
5public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
关闭线程池:
- shutdown:不再接收新任务,并且中断所有没有正在执行任务的线程
- shutdownNow:不再接受新任务,然后停止所有正在执行或暂停任务的线程
任务执行 execute:当线程数小于 corePoolSize 时,创建新的线程处理任务,否则将其放入到阻塞队列中;如果阻塞队列满,并且线程数小于 maximumPoolSize,则创建新的线程处理任务;如果线程数已经达到 maximumPoolSize,则使用 rejector 来处理
任务提交 submit:
不推荐使用 Executors 去创建线程池的原因:或者队列无限长,或者线程数量无限多,或者饱和策略失效;直接使用 ThreadPoolExecutor 的方式更加明确线程池的运行方式,规避资源耗尽的风险
监控线程池状态:
- getTaskCount & getCompletedTaskCount
- getLargestPoolSize & getPoolSize
- getActiveCount
ScheduledThreadPoolExecutor:
简介:继承自 ThreadPoolExecutor,定时或者延时启动任务,其不同点在于:
- DelayedWorkQueue:使用无界延迟队列存储任务,保证了任务只有可以执行的时候,wokrer 才能从延迟队列中取到对应的任务来执行。它只能存储 RunnableScheduledFuture 对象,并且自己实现了二叉堆用于排序
- ScheduledFutureTask:继承 FutureTask,并且实现了 Delayed 接口,表示延迟执行的任务
- 支持可选的 run-after-shutdown 参数,在池被关闭之后来决定是否执行周期或延迟任务
ScheduledFutureTask:
- run 方法:先检查是否已经到达可执行时间,然后检查是否是周期任务,如果不是,直接执行,否则将任务再次添加到队列中,并且重新设置任务的可执行时间点
- run-afetr-shutdown 参数:
- continueExistingPeriodicTasksAfterShutdown
- executeExistingDelayedTasksAfterShutdown
构造函数:
1
2
3
4
5
6public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}核心方法:
- scheduleAtFixedRate:第一次开始执行后,等待 delay 延迟执行第二次任务
- scheduleWithFixedDelay:第一次执行完成后,等待 delay 延迟执行第二次任务
ThreadPoolExecutor 饱和策略不适用于 ScheduledThreadPoolExecutor 的原因:后者使用的是无界延迟队列,maximumPoolSize 不生效,因此饱和策略也不生效
Executors 提供的方法;
- newScheduledThreadPool:可指定核心线程数的线程池
- newSingleThreadScheduledExecutor:只有一个工作线程的线程池,如果出现异常而导致线程终止,则创建新的线程来代替
ForkJoin 框架:
功能:可以将大任务划分为小任务来异步执行的工具
核心思想:
分治思想
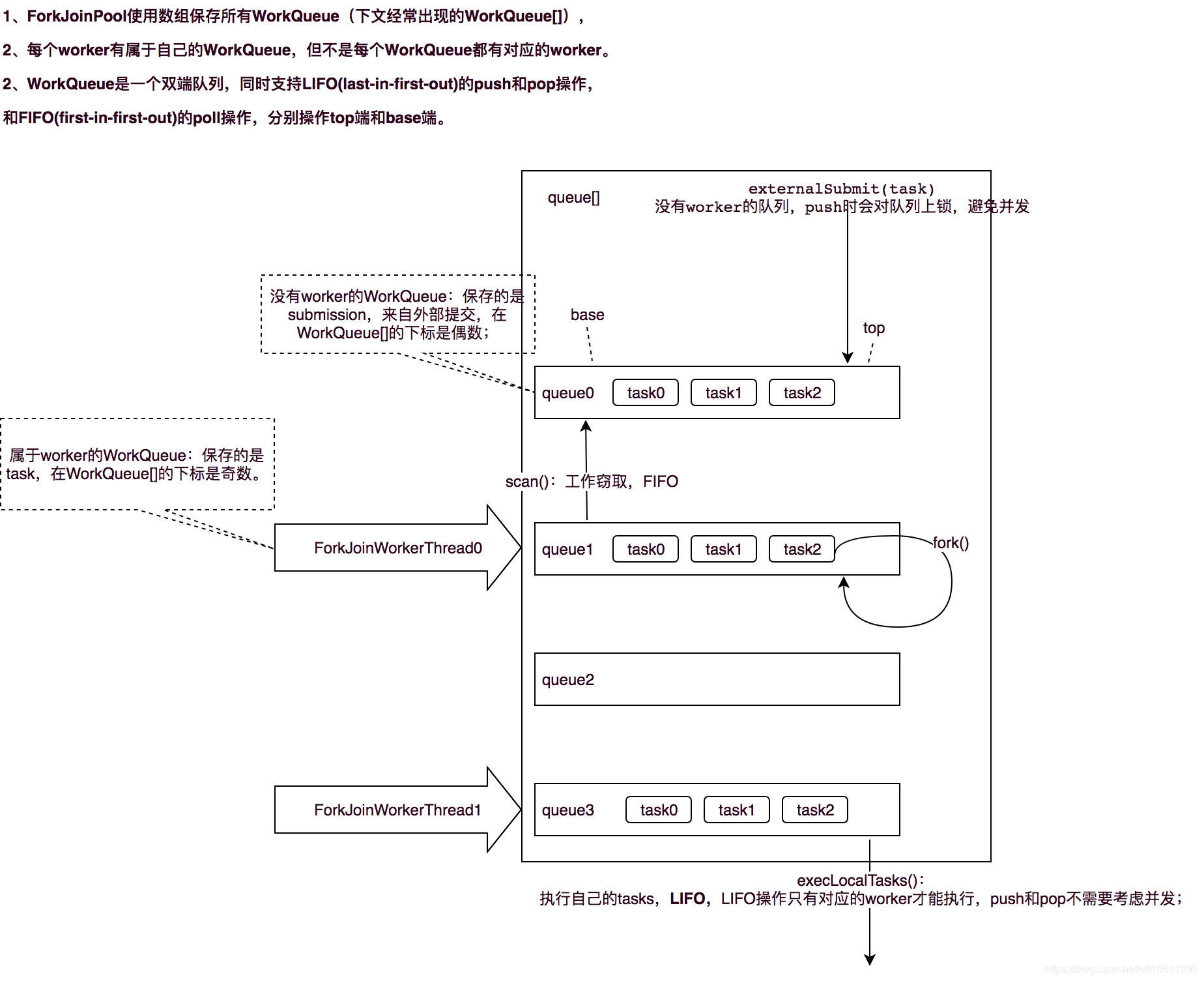
工作窃取(work-stealing)算法:工作线程优先处理来自自身队列的任务,然后以FIFO的顺序随机窃取其他队列中的任务
三个模块:
- 任务对象:ForkJoinTask,用户定义的任务可以继承以下三类
- RecursiveTask:有返回值的,可递归执行的任务
- RecursiveAction:无返回值的,可递归执行的任务
- CountedCompleter:任务完成执行后会触发执行一个自定义的钩子函数
- 执行 Fork/Join 任务的线程: ForkJoinWorkerThread
- 线程池: ForkJoinPool
- 任务对象:ForkJoinTask,用户定义的任务可以继承以下三类
执行流程:
- 直接通过 FJP 提交的外部事务(external/submissions task),存放在 workQueue 偶数槽位
- invoke:会等待任务计算完毕并返回计算结果
- execute:直接向池中提交来异步执行,无返回结果
- submit:也是异步执行,但是会返回一个 Future 对象,在适当时候通过 get 得到结果
- 通过内部 fork 分割的子任务(Worker task),存放在 workQueues 的奇数槽位
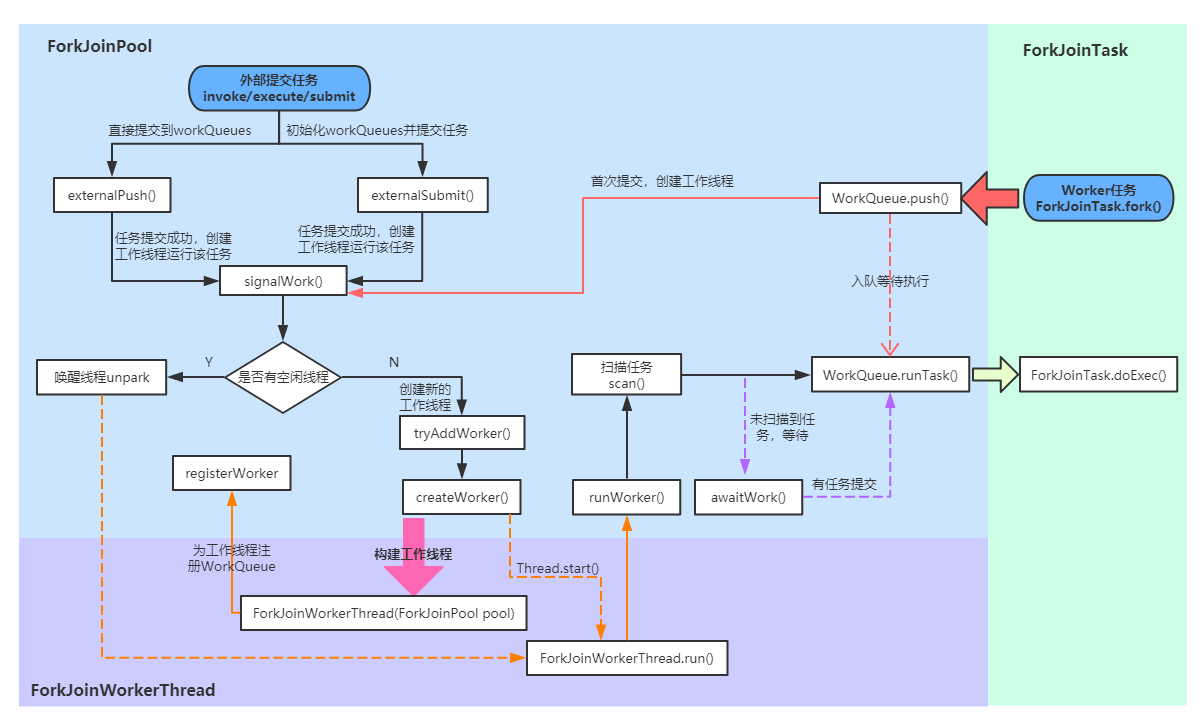
- 直接通过 FJP 提交的外部事务(external/submissions task),存放在 workQueue 偶数槽位
Fork/Join 的注意事项:
- 避免不必要的 fork:划分成两个任务后,不要都 fork,然后 join,这样会造成性能下降,可以一个任务 fork,另一个任务直接 coompute,也就是复用工作线程,不过需要注意 fork & compute & join 顺序
- 选择合适的子任务粒度:官方文档给出的任务应该执行 100-10000 个基本步骤,并且需要 JNI 预热
创建方法:
- Executors.newWorkStealingPool
- ForkJoinPool.commonPool
CountDownLatch:
- 简介:典型用法是将任务划分为 n 个独立的任务,并创建值为 n 的 CountDownLatch,通过 countDown 和 await 方法实现同步,底层通过 AQS 支持
- 核心函数:
- countDown:此函数递减锁存器的计数,如果计数值达到 0,则释放所有的等待线程
- await:锁存器计数值为 0 时,立即返回,否则将线程加入 sync queue 中等待
CyclicBarrier:
- 简介:用于同步一组线程,只有所有线程达到屏障时,屏障才会被打开,线程才能继续任务,底层通过 AQS 和 ReentrantLock 支持
- 构造函数:
CyclicBarrier(int parties, Runnable barrierAction),第二个参数用于指定所有线程都进入屏障后的执行动作,该动作由最后一个进入屏障的线程执行 - 核心方法:
- await:表示线程已经达到屏障处,对应的 count 数减 1,若所有线程都到达,则 unpark 所有线程,并且恢复计数,否则线程 park
- 和 CountDownLatch 对比:
- CountDownLatch 是一次性的,CyclicBarrier 可以重用
- CountDownLatch 下一步动作实施者是主线程,CyclicBarrier 下一步动作实施者还是其他线程本身
Semaphore:
- 简介:基于 AQS 实现,允许 n 个任务同时访问某个资源,可以将其看作是向外分发资源的许可证
- 内部类:Sync 继承自 AQS,NonfailSync 和 FailSync 继承自 Sync,用于控制是否是公平分发
- 核心方法:
- acquire:用于信号量中获取一个或多个许可,在提供一个许可前一直将线程阻塞,或者线程被中断
- release:此方法释放一个或多个许可,将其返回给信号量
- 注意:
- 不可重入性:一个线程 n 次 acquire 信号量,信号量就需要分发 n 个许可给该进程,若不够,则阻塞该进程
- 不限制最大许可大小:只要有线程 release 了许可,就会将其添加到信号量中,即使超过初始许可数
Phaser:
- 简介:可以实现 CyclicBarrier 和 CountDownLatch 类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量
- 运行机制:
- 注册机制:和其他 barrier 不同,在 Phaser 上注册的 parties 是可以动态改变的,既可以随时注册,也可以在抵达点取消注册,只会影响内部的 count
- 同步机制:既可以阻塞式等待也可以非阻塞式到达,每次所有任务达到同步点时,内部 phase 自增
- 终止机制:使用 isTerminated 来检查 phaser 的终止状态
- 分层机制:如果单个 Phaser 用来处理成千上万的任务,可能会造成因为竞争同步造成性能消耗,可以设置分层,相同层间的不同 phaser 是不存在竞争冲突的,父节点 phaser 会监控其所有孩子节点 phaser 的状态用于判断其是否可以 advance
- 状态监控:获取 parties 的数目,获取已经到达的 parties 数目
- 核心方法:
- register:为 phaser 添加一个新的 party,如果当前正在运行 onAdvance,那么就会等待它运行结束再返回结果
- arrive:是当前线程达到 phase,不等待其他任务达到就返回
- arriveAndAwaitAdvance:使当前线程到达 phaser 并等待其他任务到达
Exchanger:
- 简介:用于两个线程之间通过调用 exchange 进行数据交换
- 实现机制:当 A 线程调用 exchage 方法时,其会将数据放到 slot 中并且等待 B 线程调用 exchange;等 B 线程调用 exchange 时,此时先取 slot 中的值,并且将自己的数据放到 slot 中,最后 A 线程被唤醒,取到 slot 中的数据,就完成数据交换
- 核心属性和方法:
- arena 数组槽:slot 为单个槽,arena 为数组槽,当多个参与者使用同一个 Exchanger 时,会存在严重的伸缩性问题,通过该数组来安排不同的线程使用不同的 slot 来降低竞争问题,并且保证了最终一定会成对交换数据
- exchange:等待另一个线程到达此交换点(除非当前线程被中断),然后将给定的对象传送给该线程,并接收该线程的对象
- 和 SynchronousQueue 对比:Exchanger 是线程间安全交换数据的机制,交换了两个数据,而 SynchronousQueue 一次只交换一个数据
ThreadLocal:
- 简介:将在多线程中为每一个线程创建单独的变量副本的类,当使用 ThreadLocal 来维护变量时, ThreadLocal 会为每个线程创建单独的变量副本
- 原理:主要是利用了 Thread 对象中的 ThreadLocalMap 类型的 map 变量,其保存有 ThreadLocal 变量,第一次不存在的时候,其会调用 ThreadLocal 里面的 initialValue 创建一个初始值
- 使用场景:由于 SimpleDateFormat 并不是线程安全的,可以使用 ThreadLocal 来为每个线程创建一个 SimpleDateFormat 实例
12 Java 8 新增特性
编程方式:
- 面向对象编程:对数据进行抽象,Java 原生支持
- 面向函数编程:对行为进行抽象,Java 引入lambda 表达式,流 Stream 和改进集合类的 API 支持
lambda 表达式:
- 使用场景:
- 预定义使用了 @Functional 注释的函数式接口
- 单个抽象方法类型(SAM)
- 方法引用:可以在 lambda 表达式内使用,使用
::连接对象和方法即可,但是此时不能修改参数 - 变量捕获:可以使用静态,非静态和局部变量。需要注意,lambda 内部不能修改外部的局部变量,外部的局部变量定义在栈上,JVM 规定了栈上的数据是不需要同步操作的,修改后将产生同步问题
- JVM 实现:lambda 方法在编译器内部被翻译成私有静态方法,通过 invokedynamic 指令进行调用
内置四大函数接口:
- 消费型接口:
Consumer<T> void accept(T t) - 供给型接口:
Supplier <T> T get() - 断定型接口:
Predicate<T> boolean test(T t) - 函数型接口:
Function<T,R> R apply(T t)
流:更高的抽象层次上对集合数据进行操作
- 分类:Stream 和 parallelStream
- 常用方法:filter,sorted,forEach,map,reduce,distinct,limit,count,min,max,collect,summaryStatistics
Optional 类:
- 功能:可以为 null 的对象容器,提高 null 的安全性
- 主要方法:
- of,ofNullable
- isPresent,get
- ifPresent,orElse,orElseGet,orElseThrow
- map,flatMap
- filter
- 性能:可能没有传统方法
obj != null高性能,但是大多数情况下不会有问题,可用在流处理上
默认方法:
- 简介:接口可以有实现方法,而且不需要实现类去实现该方法,使用关键字 default 即可
- 作用:为了兼容,之前的接口不支持默认方法的实现,如果想要修改接口,就需要修改所有的实现类,但是默认方法就可以实现扩展接口并且不修改对应的实现类,实现了向下兼容
- 多重实现的冲突:同一个方法可以在不同接口引入,会有冲突产生,判定规则:
- 一个声明在类里面的方法优先于任何默认方法,可以使用
interfaceName.super.methodName() - 否则,则会优先选取路径最短的,若路径最短的有多个,则报错
- 一个声明在类里面的方法优先于任何默认方法,可以使用
类型注解:
- 简介:Java 8 之前注解只能用在类,方法,属性上,而在 Java 8 中,注解可以用在更大的范围上。类型注解只是语法而不是语义,并不会影响 java 的编译时间,加载时间,以及运行时间,也就是说,编译成 class 文件的时候并不包含类型注解
- 作用:用来支持在 Java 程序中做强类型检查,如 @NonNull,配合插件式的 check framework,可以检测出一些 runtime error,从而提高代码质量
- 向下兼容:在 Java 8 版本下,将类型注解使用块注释注释掉
重复注解:
- 简介:允许在同一声明类型中多次使用同一个注解
- 实现:
- Java 8 之前:由 A 注解保存重复注解 B,使用 A 即可
- Java 8:创建重复注解 B 时,使用 @Repeatable 指向 A 注解的 Class 对象,使用时多次使用 B 即可,可读性更强
类型推断优化:支持菱形语法
JRE 精简:
- 优点:需要更少的计算资源,启动时间增加,消除未使用的代码安全性提升,适应物联网
- 划分:compact1 < compact2 < compact3 < Full JRE
移除永久代(PermGen):
简介:在 Java 7 中,永久代主要用来存储一些 Class 和 Meta 的信息,在 Java 8 中被移除,取而代之的是元空间,JVM 内存结构如图:
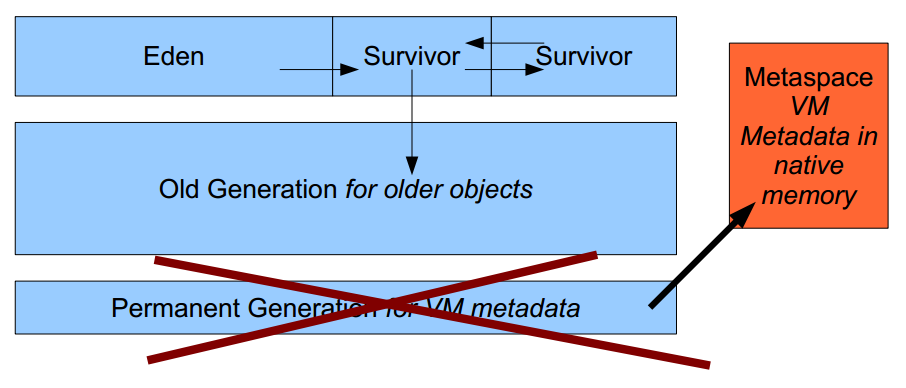
Java8 元空间:
- 大部分类元数据都在本地内存中分配
- 通过 MaxMetaspaceSize 限制元空间大小
- 只有达到 MaxMetaspaceSize 阈值才会进行垃圾回收
- 一些杂项数据移动到 Java 堆空间中,堆空间容量可能会有所增加
StampedLock:
- 同步实现方法:
- synchronized:重量级锁,在 Java6 中有所优化,通过 JVM 实现,代码异常时能够自动释放锁
- Lock:接口,核心方法是 lock,unlock,trylock,实现类基本通过 AQS 来实现,相较于 synchronized,提供了定时锁等候和中断锁等候,unlock 必须放在 finally 语句里面
- StampedLock:支持乐观读、悲观读锁和写锁,支持多个线程申请乐观读的同时,还允许一个线程申请写锁,底层并不是通过 AQS 来实现的,而是通过 state 和一个队列实现,不支持重入
- 优点:相较于 Lock,其在读多写少的场景下性能提升较大
LocalDate/LocalDateTime:
- Java 中时间类演化:
- Java 1.0:Date 既要承担日期信息,又要做日期之间的转换,还要做不同格式日期的显示
- Java 1.1:日期时间类分开,Date + Calendar + DateFormat,但是存在以下问题:
- year 和 month 是从 1900 开始偏移的,month 是从 0 开始偏移的
- Date 和 Calendar 所有属性是可变的
- SimpleDateTimeFormat 非线程安全
- Java 1.8:引入 java.time 包,里面的类是不可变的并且是线程安全的,其中的类:
- Instant:时间戳
- LocalDate:日期
- LocalTime:时间
- LocalDateTime:包含日期和时间
- ZonedDateTime:包含时区的完整的日期信息
面试合集
Java 中应该使用什么数据类型来代表价格?
如果不是特别关心内存和性能的话,使用 BigDecimal,否则使用预定义精度的 double 类型
怎么将 byte 转换为 String?
使用 new String(byte[] bytes) 创建,注意需要使用正确的编码
Java 中怎样将 bytes 转换为 long 类型?
先将其转换为 String,再使用 Long.parseLong
存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么? 如 C = (C) B;
可以,向下转型,不安全,容易出现转型异常
哪个类包含 clone 方法? 是 Cloneable 还是 Object?
Object,Cloneable 只是一个标识性接口,不包含任何方法
a = a + b 与 a += b 的区别?
+= 隐式的将加操作的结果类型强制转换为持有结果的类型,如果两个整型(byte,short,int)相加,首先会将其提升到 int 类型,再执行加法操作
int 和 Integer 哪个会占用更多的内存?
Integer,其需要额外存储对象的元数据
我们能在 Switch 中使用 String 吗?
从 Java 7 开始可以,但实际上是语法糖
我们可以在 hashcode() 中使用随机数字吗?
不可以,相同对象的哈希值必须相同
Java 中,Comparator 与 Comparable 有什么不同?
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
final、finalize 和 finally 的不同之处?
- final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变
- Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,但是什么时候调用 finalize 没有保证
- finally 是一个关键字,与 try 和 catch 一起用于异常的处理。finally 块一定会被执行,无论在 try 块中是否有发生异常
Java 中,Serializable 与 Externalizable 的区别?
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许你控制整个序列化过程,指定特定的二进制格式,增加安全机制。
异常关键字:throw、throws、try…catch、finally?
throws 用在方法签名上,方法内部通过 throw 抛出异常,try 用于检测包住的语句块, 若有异常, catch子句捕获并执行catch块
finally 执行时机?
当 try 和 catch 中有 return 时,finally 仍然会执行,finally 比 return 先执行,finally是在 return 后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在 finally 执行前确定的,通常,finally 里面不要包含 return,否则程序会提前退出
如何创建内部类和静态内部类对象?
内部类:new OuterClass.new InnerClass;静态内部类:new OuterClass.StaticInnerClass
不需要序列化的字段?
声明为static和transient类型的数据不能被序列化, 反序列化需要一个无参构造函数
局部变量为什么要初始化?
局部变量分布在栈上,生命周期短,JVM 并不会主动初始化而降低自己的性能,因此,需要程序员在使用变量前给变量赋值